Meta did something weird in February 2023. They released a research paper and a set of weights for a new collection of models. It wasn't a product like ChatGPT. You couldn't just "chat" with it on a website. But LLaMA open and efficient foundation language models effectively lit the fuse for the explosion of local AI we see today.
Before LLaMA, if you wanted to play with a massive language model, you basically had to beg a giant corporation for API access. It was a gated garden. Then, the weights leaked on 4chan—which is a bizarre sentence to write about world-class technology—and suddenly, the academic world and the "hacker" community had their hands on the raw materials.
Everything changed.
The "Small but Mighty" Philosophy
Most people assume bigger is always better in AI. They think you need a trillion parameters to get a coherent sentence. Meta’s research team, led by folks like Guillaume Lample and Hugo Touvron, proved that was a lie. They focused on LLaMA open and efficient foundation language models that were trained on way more tokens than what was considered "optimal" at the time.
The Chinchilla scaling laws suggested that if you have a certain amount of compute, you should balance the model size and the data size. Meta ignored that. They trained their smaller models—like the 7B and 13B versions—for much longer on a massive corpus of 1.4 trillion tokens.
Why? Because a small model that is "over-trained" is much cheaper to run once it's finished.
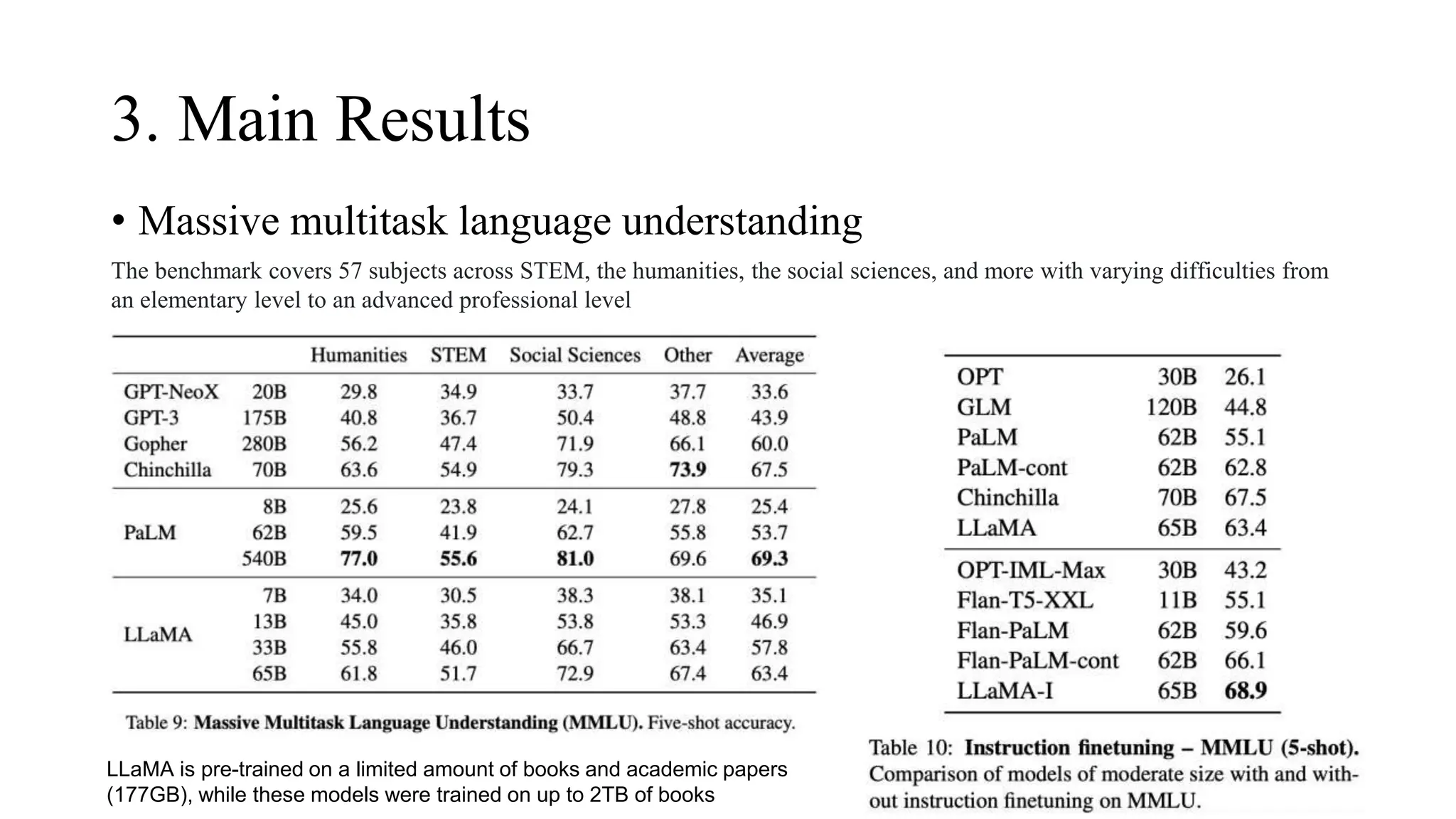
It’s about inference. If you’re a developer, you don’t want a model that requires a $40,000 GPU just to say "Hello." You want something that fits on a MacBook or a high-end phone. LLaMA made that possible. It proved that a 13-billion parameter model could outperform the original GPT-3 (175B parameters) in many benchmarks. That is a massive efficiency gain.
Honestly, it's the difference between a gas-guzzling semi-truck and a turbocharged sports car. Both get you there, but one is a lot easier to park in your garage.
🔗 Read more: What Structures Can Differentiate Between a Plant and Animal Cell: The Real Biology Most People Forget
What "Open" Actually Means Here
We need to be real about the word "open."
Meta didn't release LLaMA as "Open Source" in the way the OSI (Open Source Initiative) defines it. You couldn't just use it for whatever you wanted initially; it was for research. But compared to the black boxes of OpenAI or Google’s Gemini, it was a revolution. By providing the weights, Meta allowed researchers to see the "brain" of the AI.
Think of it like a recipe.
- OpenAI gives you the finished cake through a window.
- Meta gave you the exact measurements of every ingredient and the oven settings.
This transparency allowed for techniques like LoRA (Low-Rank Adaptation). Without the foundation of LLaMA, we wouldn't have Alpaca, Vicuna, or the thousands of fine-tuned models currently sitting on Hugging Face. These derivative models allowed the community to "instruct-tune" AI to follow directions, often for less than $600 in compute costs. That’s insane.
The Architecture Breakdown
LLaMA wasn't a total reinvention of the wheel. It used the Transformer architecture, but with a few clever tweaks that made it more stable and efficient:
- Pre-normalization (RMSNorm): Instead of normalizing the output, they normalize the input of each transformer sub-layer. It keeps the gradients from exploding.
- SwiGLU Activation Function: A mouthful to say, but it basically helps the model learn more complex patterns than the standard ReLU used in older models.
- Rotary Embeddings (RoPE): This is the secret sauce for how the model remembers the position of words. It’s much more elegant than the absolute positional embeddings used in the early days of GPT.
Why Efficiency is the Real Goal
If you look at the energy consumption of data centers, it’s terrifying. We can't just keep building bigger models. LLaMA open and efficient foundation language models represent a shift toward sustainability.
When LLaMA 2 and LLaMA 3 eventually followed, the focus remained on density. How much knowledge can we cram into a 7B or 8B parameter model? It turns out, a lot. LLaMA 3 was trained on over 15 trillion tokens. That’s a staggering amount of text. By the time the model gets to you, it has "read" almost everything useful on the public internet multiple times over.
But there’s a catch.
These models still hallucinate. They still get confident about things that are objectively wrong. Efficiency doesn't always mean "accuracy." It just means the model is better at using its internal logic. You still need RAG (Retrieval-Augmented Generation) if you want it to talk about your specific company data without making stuff up.
The Impact on the "Moat"
There was a famous leaked memo from a Google engineer titled "We Have No Moat, and Neither Does OpenAI." The premise was simple: while the giants were fighting each other, the open-source community using LLaMA was winning.
People were getting 90% of the performance of ChatGPT on their own hardware.
👉 See also: Why This Action is Not Allowed with This Security Level Configuration Keeps Popping Up
If you're a business, this is huge. You don't have to send your sensitive customer data to a third-party server. You can run a LLaMA-based model behind your own firewall. It’s about sovereignty. You own the model. It doesn't change or get "lobotomized" overnight because a provider decided to update their safety filters.
Real-World Limitations
We shouldn't pretend LLaMA is perfect. It's not.
One major issue is the context window. Early versions had a very short "memory." If you gave it a long document, it would forget the beginning by the time it reached the end. While LLaMA 3 expanded this significantly, it still lags behind models like Gemini 1.5 Pro, which can handle millions of tokens.
Also, the bias issue. Because these models are trained on the internet, they reflect the internet. The good, the bad, and the ugly. Meta puts in a lot of work on "Llama-Guard" and safety tuning, but the raw foundation models are exactly that—raw. They require careful handling.
How to Actually Use This Today
If you want to start with LLaMA open and efficient foundation language models, you don't need a PhD.
- Ollama: This is the easiest way. Download it, type
ollama run llama3, and you're chatting with a world-class AI on your laptop in seconds. - LM Studio: If you prefer a GUI (Graphical User Interface), this lets you search for any version of LLaMA on Hugging Face and run it locally.
- vLLM: If you are a dev trying to serve a model for an app, this library is the gold standard for high-throughput inference.
The era of "AI as a Service" is being challenged by "AI as an Asset."
Actionable Next Steps
To get the most out of the LLaMA ecosystem, start by identifying your specific needs rather than just "trying AI." If you are a developer, pull the LLaMA 3 8B weights and experiment with fine-tuning on a niche dataset using Unsloth—it’s a library that makes the process much faster and uses less VRAM.
For business owners, look into deploying LLaMA via a local provider like Groq. They use specialized hardware (LPUs) that makes LLaMA run at hundreds of tokens per second, which feels instantaneous. This removes the latency bottleneck that kills most AI user experiences.
Finally, keep an eye on the "Quantization" community. People are finding ways to shrink these models from 16-bit to 4-bit or even 1.5-bit precision with almost no loss in "intelligence." This is the true path to getting a genius-level assistant in your pocket that doesn't need an internet connection.