Building AI isn't the problem anymore. Scaling it is. You've probably seen the flashy press releases or caught Michael Dell and Jensen Huang cracking jokes on stage together, but behind the marketing jargon, there’s a massive technical shift happening. The Dell AI Factory with NVIDIA isn't just a fancy name for a server rack. It’s a full-stack response to the fact that most companies are currently failing to move their AI projects out of the "cool demo" phase and into actual production.
Most IT departments are drowning. They’re trying to stitch together disparate GPUs, networking cables, and software libraries from a dozen different vendors, and honestly, it’s a mess.
Why the Dell AI Factory with NVIDIA actually exists
We need to talk about the "Day 2" problem. Anyone with a credit card can rent an H100 instance in the cloud for an afternoon to train a small model. That’s Day 1. Day 2 is when you realize your data is trapped in an on-premise silo, your latency is killing your real-time inference, and your CFO is screaming about unpredictable egress fees. The Dell AI Factory with NVIDIA was designed to stop that bleeding by creating a blueprint that looks the same whether it's in a core data center, a colocation facility, or out at the edge.
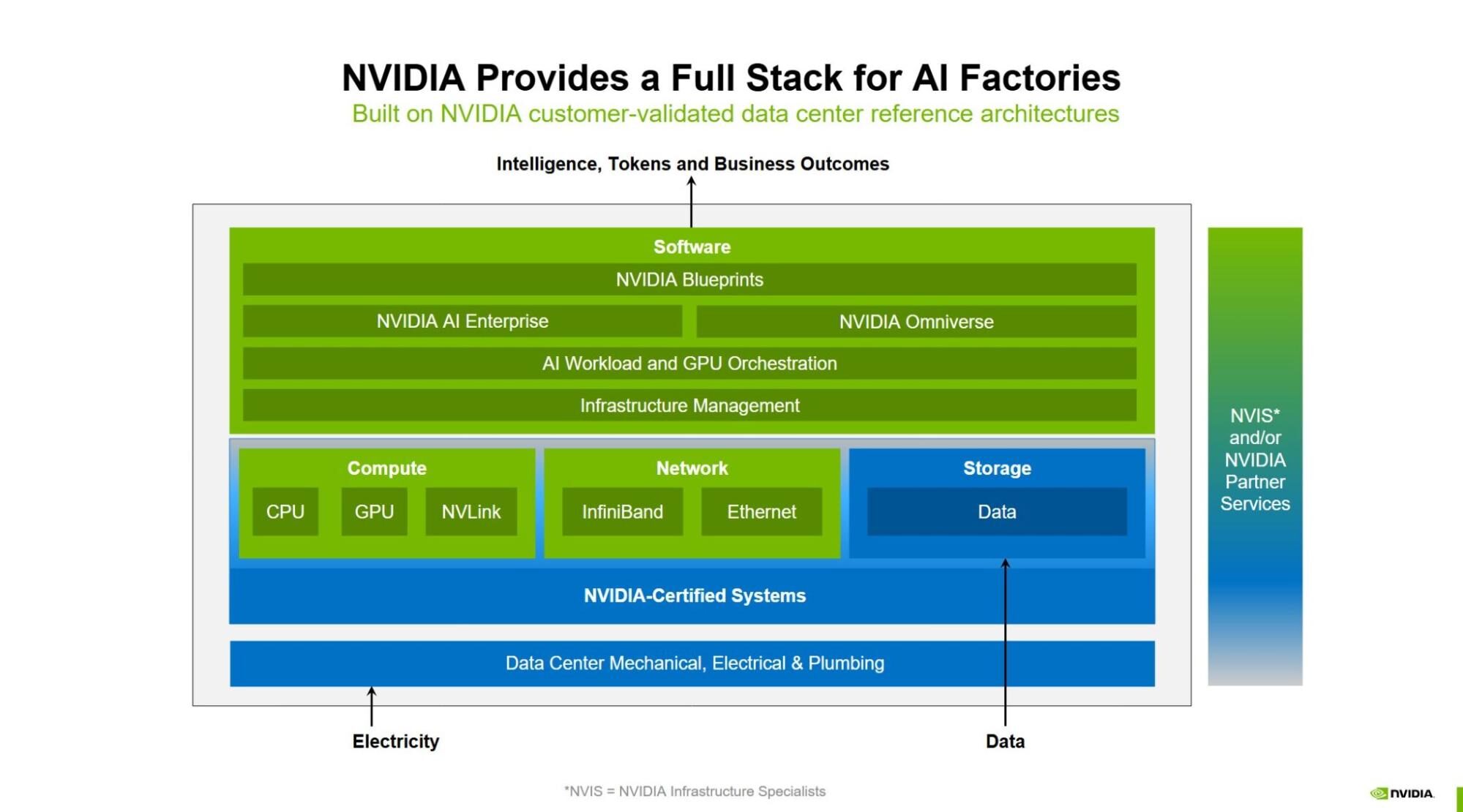
It's essentially a pre-validated ecosystem. Think of it as the difference between buying a bag of loose engine parts and buying a tuned race car. You get the PowerEdge servers—specifically the XE9680 which is basically the gold standard for this stuff—packed with NVIDIA H100 or H200 Tensor Core GPUs. But the hardware is only half the story.
👉 See also: Headphone Out to USB: Why Most People Get the Connection Backwards
The secret sauce is the integration of the NVIDIA AI Enterprise software platform. If you’ve ever tried to manage CUDA versions across a cluster of a hundred nodes manually, you know it’s a special kind of hell. This setup automates that. It's about getting from "we have an idea" to "the model is live" without your DevOps team quitting in frustration.
The hardware stack is getting ridiculous
The PowerEdge XE9680 is a beast. It supports eight NVIDIA GPUs interconnected with NVLink. That matters because when you're training a Large Language Model (LLM), the bottleneck often isn't the compute power of a single chip; it’s how fast those chips can talk to each other. If the chips are waiting for data, you're burning money.
Dell also rolled out the XE9680L, which is a liquid-cooled version. Why? Because these things run hot. Like, "melt your standard data center cooling" hot. By moving to liquid cooling, you can pack more density into a smaller footprint. You’re looking at better rack density and, frankly, a much lower chance of your hardware throttling during a heavy training run.
Data is the biggest hurdle
You can't have an AI factory without raw materials. In this case, that’s your data. Most enterprise data is messy, unstructured, and scattered across different storage platforms. Dell’s PowerScale (their F910 all-flash storage) is now the first ethernet-based storage to be validated for NVIDIA DGX SuperPOD.
What does that mean for you? It means you don't necessarily need to move all your data to the cloud to use it. You can keep it on-prem, where it’s secure, and feed it directly into the GPUs at speeds that keep the processors busy.
Putting RAG into practice
Retrieval-Augmented Generation (RAG) is the current darling of the enterprise world. It’s how you stop an AI from hallucinating by giving it access to your actual company documents. The Dell AI Factory with NVIDIA includes specific "blueprints" for RAG.
💡 You might also like: Why China's Shandong Aircraft Carrier Changes Everything in the Pacific
Instead of starting from a blank text file, you get a documented path:
- Use Dell PowerEdge for compute.
- Use NVIDIA NeMo microservices (NIMs) for the model orchestration.
- Connect to a vector database sitting on Dell storage.
It works. It's predictable. It's boring in the best way possible because boring means it doesn't break at 3 AM.
The software layer: NVIDIA NIM
We have to mention NIMs. These are essentially "inference in a box." Before NIMs, deploying a model meant writing a bunch of custom wrapper code to handle API calls, scaling, and logging. It was tedious. NVIDIA basically containerized the entire stack—the model, the engine, and the dependencies—so you can drop it onto the Dell hardware and it just runs.
This allows companies to use "sovereign AI." It’s a big term that basically means "keeping your stuff in your own house." If you’re a bank or a healthcare provider, you can’t exactly ship your customer data off to a third-party API and hope for the best. You need to run the model locally. The Dell-NVIDIA partnership makes this viable for companies that aren't Google or Meta.
Reality check: It isn't cheap
Let’s be real. Setting up a private AI factory is a massive capital investment. We are talking millions of dollars for a full-scale deployment.
There are also power constraints to consider. A single rack of these high-end GPU servers can pull 100kW or more. Most older data centers simply aren't built for that. You might find yourself needing to upgrade your entire electrical and cooling infrastructure before the first server even arrives.
But here is the counter-argument: the cost of not doing it. If your competitor is using AI to automate their entire supply chain or provide 24/7 hyper-personalized customer support, and you’re still stuck in a pilot program, you’re in trouble. Dell offers "APEX," which is their consumption-based model. It basically lets you pay for the AI factory as a service, turning a giant CAPEX hit into a more manageable OPEX line item. It's a way for mid-sized players to get into the game without betting the entire farm upfront.
What about the "Open" part?
Dell and NVIDIA talk a lot about being "open," but you're obviously locking into their ecosystem to a degree. However, they are supporting open-source models like Llama 3. The idea is that the infrastructure is proprietary and optimized, but the models you run on it don't have to be. You can take a model from Hugging Face, optimize it using NVIDIA’s TensorRT, and deploy it on Dell hardware. That flexibility is crucial because the "best" model changes every three months. You don't want to be locked into a specific LLM that becomes obsolete by next Tuesday.
Where this is actually being used today
We are seeing some fascinating use cases. Northwestern Medicine is using this tech to help doctors summarize patient notes and predict outcomes. In manufacturing, companies are using digital twins—powered by NVIDIA Omniverse running on Dell servers—to simulate entire factory floors before they even move a single piece of equipment.
It's not just about chat bots. It’s about high-fidelity simulation and massive data processing.
Getting started without losing your mind
If you’re looking at the Dell AI Factory with NVIDIA and wondering where to start, don't try to build the whole thing at once. Start with a "Proof of Concept" (POC) on a single XE9680 node.
- Identify the Data: Don't try to feed the AI everything. Pick one clean, valuable dataset (like your knowledge base or product catalog).
- Use a Blueprint: Don't reinvent the wheel. Use the Dell-validated designs for RAG or digital twins.
- Think About Cooling Early: If you’re going for the high-density stuff, talk to your facilities manager today. Like, right now.
- Focus on NIMs: Use NVIDIA NIMs to speed up deployment. It will save your developers weeks of work.
The goal is to create a repeatable process. A factory is defined by its ability to produce consistent results at scale. That is exactly what this partnership is trying to provide to the enterprise world. It’s moving AI from a science experiment to a standard utility.
Practical Next Steps for Your Team
Stop thinking about AI as a "software project" and start treating it like a specialized manufacturing line. Your first move should be an infrastructure audit. Can your current data center handle the power and cooling requirements of an H200 cluster? If the answer is no, look into Dell’s modular data center options or a colocation partner that is specifically "AI-ready."
Next, prioritize your data strategy. The AI factory is only as good as the data you feed it. If your data is siloed in legacy systems, your first investment shouldn't be in GPUs; it should be in a modern data lakehead like PowerScale that can actually feed those GPUs. Once the plumbing is fixed, the "factory" part becomes a lot easier to manage.