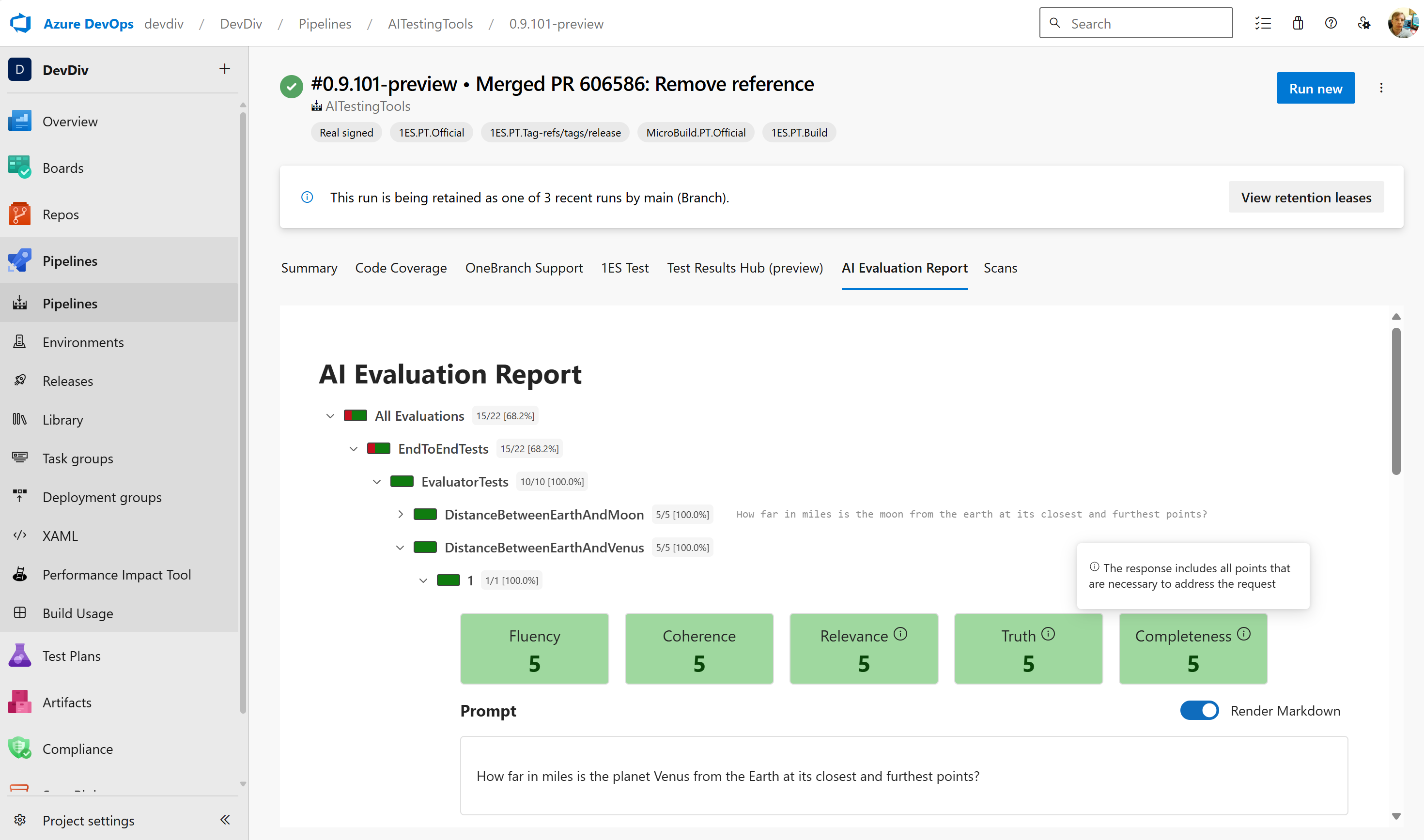
The way we measure artificial intelligence right now is, frankly, a bit of a mess. You’ve probably seen the leaderboards. Every week, a new model drops—GPT-5, Claude 4, or some specialized open-source variant—and they all claim to be the smartest thing ever built because they scored a 90% on a test called MMLU. But then you actually use the model to help with your taxes or write a script, and it hallucinates a law that doesn't exist.
What gives?
The reality is that we’ve been treating AI like a calculator that needs its buttons checked. We give it a static list of questions, it spits out answers, and we tally the score. But as these systems start acting more like "reasoning agents" and less like autocomplete, that approach is hitting a wall. Honestly, the industry is starting to realize that AI evaluation should learn from how we test humans.
We don't judge a doctor’s competence solely by a multiple-choice quiz they took once in 2022. We use board exams, clinical rotations, and peer reviews. We need to start bringing that same "human" nuance to the silicon.
The Problem With the Static Benchmark
Most current AI benchmarks are what researchers call "static." It’s a fixed set of questions. If you’re a developer, the temptation to (even accidentally) include those questions in your training data is massive. It’s called data contamination. It’s like a student getting a copy of the SAT the night before the big day. They aren't smarter; they just have a better memory.
A 2024 study on the GSM8K math benchmark found that some models were basically just "memorizing" reasoning steps. When researchers changed the numbers slightly or shifted the wording, the "genius" AI suddenly couldn't add two plus two.
Static tests also suffer from "saturation." In late 2025, we saw models hitting 98% or 99% on standard coding tests. Does that mean the AI is a perfect coder? No. It just means the test is too easy for the current generation of tech. We’ve reached the ceiling, and the view isn't actually that great.
Borrowing From Psychometrics
If you’ve ever taken the GRE or the GMAT, you’ve experienced Adaptive Testing. This is a pillar of psychometrics—the science of measuring mental capacities. When you get a question right, the next one gets harder. If you miss it, the test scales back to find your "floor."
Recent position papers, like those presented at ICML 2025, argue that this is exactly where AI testing needs to go. Instead of a 5,000-question slog, we should use Item Response Theory (IRT).
Basically, IRT doesn't just look at whether an answer is right or wrong. It looks at the difficulty and discrimination of the question. If a "dumb" model and a "smart" model both get a question right, that question isn't helping us differentiate them. Psychometrics teaches us to find the "latent traits"—the underlying ability to reason—rather than just counting correct bubbles.
The "Vibe" Check vs. The "Board" Exam
We often hear about "Chatbot Arena" or "LMSYS" rankings. These rely on humans picking which AI response they like better. It’s a "vibe check." And while vibes matter for consumer products, they are a terrible way to evaluate high-stakes reliability.
Think about how we test a lawyer. We don't just ask people, "Does this guy sound like a lawyer?" We put them through a Bar Exam that tests specific, edge-case logic.
Stanford’s HELM (Holistic Evaluation of Language Models) is trying to bridge this gap. Instead of one score, they look at:
- Accuracy: Did it get the facts right?
- Robustness: If I insult the AI, does it stop working?
- Fairness: Does it give different medical advice to different demographic groups?
- Copyright: Is it just quoting a New York Times article verbatim?
This is much closer to how we evaluate human professionals. We look at the whole person—or in this case, the whole model.
Why Interaction Is the New Gold Standard
One of the coolest shifts happening right now is the move toward evaluating AI as an agent.
When you hire an intern, you don't just give them a quiz. You give them a task: "Research this company and draft a 5-page memo." You see how they handle obstacles. Do they ask clarifying questions? Do they give up when a website is down?
✨ Don't miss: Finding a Tornado on Google Maps: Reality vs. Internet Myths
Companies like Anthropic and OpenAI have started using "long-horizon" tasks. They drop the AI into a simulated computer environment and tell it to fix a software bug. This is performance-based assessment. It’s the difference between knowing the definition of a "clutch" and actually knowing how to drive a manual transmission.
In a joint safety exercise in late 2025, researchers found that models like Claude 4 and GPT-5 handled "instruction hierarchy" differently. One might be great at following rules but terrible at creative problem-solving when those rules conflict. Testing them "in the wild" revealed flaws that a static Q&A never would have caught.
Practical Steps for the Real World
If you’re a business leader or a dev trying to figure out which AI to actually use, stop looking at the top-line benchmark scores. They are mostly marketing fluff at this point.
Instead, build your own "Human-Style" evaluation pipeline:
- Create a "Hidden" Eval Set: Never use public benchmarks. Gather 50-100 real-world prompts from your actual users. Keep them in a private vault so the AI labs can't scrape them into their training data.
- Test for "Calibration": A smart human knows when they don't know something. Ask the AI questions it couldn't possibly know and see if it says "I don't know" or if it makes up a convincing lie.
- Use "LLM-as-a-Judge" (With Caution): You can use a very strong model (like GPT-4o or o1) to grade the output of a smaller, faster model. But remember, AI "judges" tend to prefer longer answers, even if they are fluffier. Always have a human spot-check the grader.
- Evaluate the "Process," Not Just the "Output": If you're using a reasoning model, look at the chain of thought. Is the logic sound? Even if the final answer is right, "lucky" logic is a red flag for future failures.
We are moving out of the era of "AI as a tool" and into "AI as a collaborator." If we want to know if we can trust these systems, we have to stop treating them like software and start testing them like the complex, unpredictable entities they’ve become. The path forward isn't more data; it's better, more "human" testing.
📖 Related: Why the Trailer Tail on Semi Trucks Actually Disappeared
Actionable Next Steps:
- Audit your current AI metrics: If you are relying on MMLU or HumanEval scores to choose a model, stop.
- Draft a "Red Teaming" document: List 10 ways your specific business use case could go wrong (e.g., the AI gives a discount it shouldn't) and test specifically for those failures.
- Investigate Adaptive Testing tools: Look into frameworks that use IRT or dynamic item selection to get a more granular view of model performance beyond a simple percentage.