You've probably been there. Your microservices are a mess. It's a literal "spaghetti" situation where one service calls another, which calls another, and suddenly, you have no idea why a customer’s order just vanished into the ether. So, you look for an open source workflow engine. It sounds like the perfect fix. You get visibility, retries, and state management without the vendor lock-in of a proprietary cloud service. But here is the thing: most people pick the wrong one or, worse, they use it for the wrong reasons.
Code is messy. Business logic is messier.
When you dive into the world of orchestration, you’re basically trying to manage "long-running processes." This could be anything from a 30-second credit card validation to a three-week onboarding sequence for a new hire. If the server reboots in the middle, does the process die? If the answer is yes, you need a workflow engine. If the answer is no, you’re just adding latency for fun. Honestly, I've seen teams spend six months migrating to Camunda or Temporal only to realize they could have just used a simple database flag and a cron job.
The Reality of Choosing an Open Source Workflow Engine
The landscape has changed. A few years ago, everything was about BPMN (Business Process Model and Notation). It was that "low-code" dream where business analysts would draw diagrams and—poof—code would happen. Spoiler alert: it didn't work. The diagrams became unreadable nests of XML that developers hated.
Now, we see a massive shift toward "as-code" workflows.
The Big Players Right Now
If you're looking at GitHub stars and production reliability, you’re mostly looking at three or four specific projects.
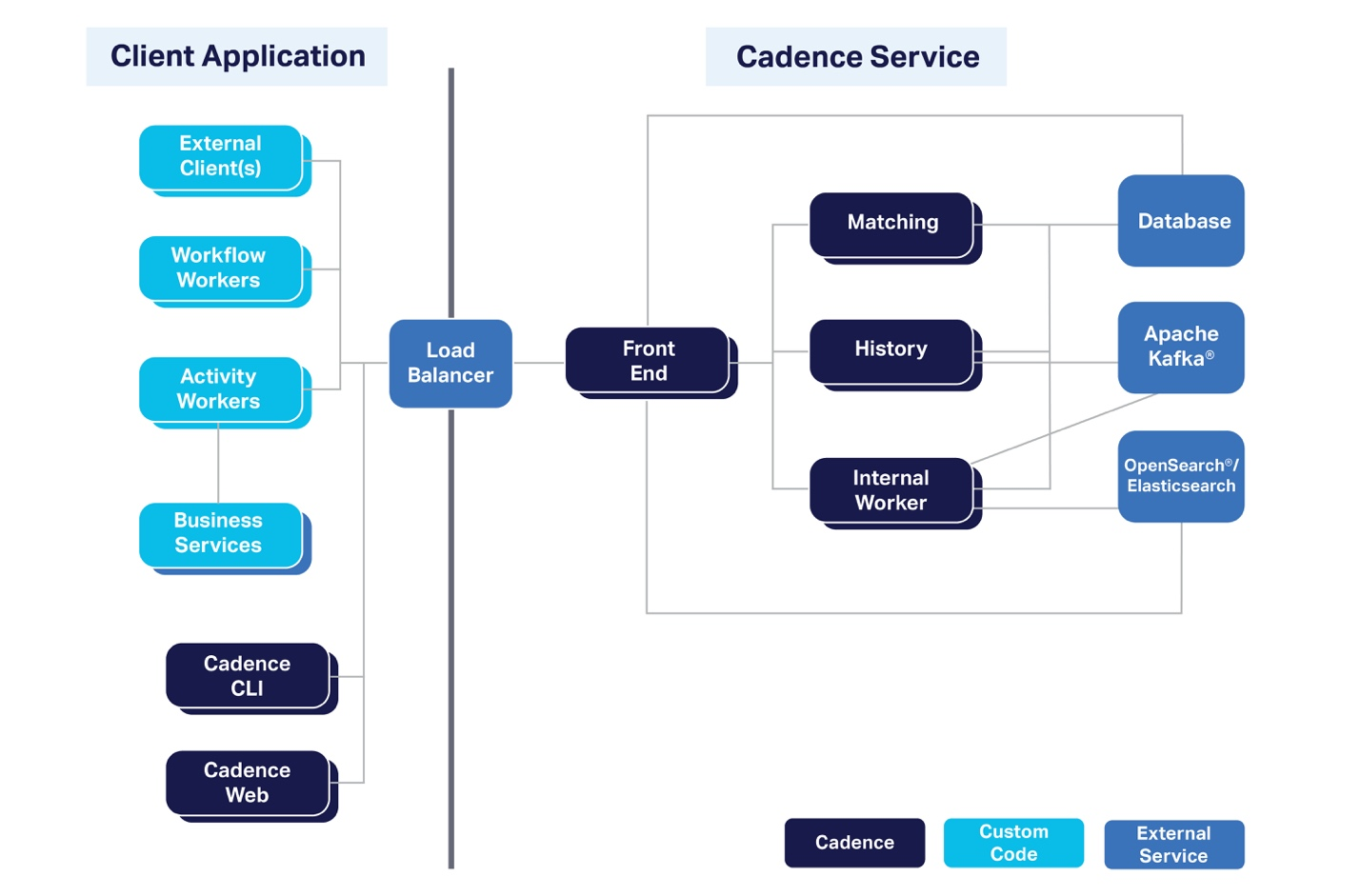
Temporal is the heavy hitter. It spun out of Uber’s Cadence. It’s not really a "workflow" engine in the traditional sense; it’s more like a way to make your code invincible. You write standard Go, Java, or TypeScript, and Temporal ensures that the state is preserved even if the entire data center melts down. It’s brilliant, but the learning curve is steep. You have to think about "determinism," which is a fancy way of saying your code can't have random numbers or current time checks inside the workflow logic. If you mess that up, the whole thing breaks.
📖 Related: Installing a Push Button Start Kit: What You Need to Know Before Tearing Your Dash Apart
Then there is Camunda. They’ve been around forever. They recently shifted from the old-school Camunda 7 (based on a local engine) to Camunda 8, which uses a high-performance engine called Zeebe. It still loves BPMN. If your boss really wants to see a visual map of what’s happening, Camunda is usually the winner. But be careful—the licensing for their "open" versions has become a bit of a maze lately.
Don't forget Airflow. Look, Airflow is great for data. If you’re moving petabytes of data from S3 to Snowflake, use it. But please, stop using Airflow for microservices orchestration. It wasn't built for high-frequency, low-latency API calls. It’s like using a freight train to deliver a single pizza.
What Nobody Tells You About State Management
Every open source workflow engine works by "checkpointing." Every time your code hits a "step," the engine writes the state to a database.
This is expensive.
If you have a high-throughput system doing 10,000 requests per second, a workflow engine might actually be your biggest bottleneck. You’re trading performance for reliability. Is that trade worth it? Usually. But don't act surprised when your database CPU spikes because your engine is screaming at it to save every little variable change.
Why "Open Source" Isn't Always Free
We love open source because we can read the code. We hate it because we have to manage the infrastructure.
👉 See also: Maya How to Mirror: What Most People Get Wrong
Setting up a production-grade open source workflow engine usually requires:
- A high-availability database (Postgres, MySQL, or Cassandra).
- An ingest layer (like Kafka or a proprietary protocol).
- Monitoring (Prometheus/Grafana).
- Worker nodes that actually execute your code.
Basically, "free" software often costs $10,000 a month in DevOps salaries.
I talked to a lead engineer at a fintech startup last year who bragged about saving $50k by moving off AWS Step Functions to a self-hosted engine. Then I asked how many engineers were maintaining it. Two. Full-time. You do the math.
The Determinism Trap
This is where beginners get wrecked. In engines like Temporal or Cadence, the engine "replays" your code to get back to a certain state. If your code does this:
if (Math.random() > 0.5) {
doActionA();
} else {
doActionB();
}
The engine will lose its mind. During a replay, the "random" result might change, and the engine will see that the history doesn't match the code. It will throw a non-deterministic error and your workflow will get stuck in a loop forever. You have to use the engine’s built-in "Side Effects" or "Activities" to do anything that isn't 100% predictable. It’s a totally different way of programming. It’s basically functional programming with extra steps and more anxiety.
When to Actually Use One
Don't just add a dependency because it's trending on Hacker News. Use an open source workflow engine if you have:
✨ Don't miss: Why the iPhone 7 Red iPhone 7 Special Edition Still Hits Different Today
- Human-in-the-loop tasks: You need a process to wait three days for a manager to click "Approve."
- Complex Sagas: You need to charge a card, then book a flight, then book a hotel. If the hotel fails, you must refund the flight and the card. Doing this manually with "if/else" statements is a nightmare.
- Exponential Backoff: You’re calling a flaky third-party API that fails 20% of the time. The engine handles the retries so you don't have to write "sleep" loops.
Practical Steps for Implementation
If you’ve decided to take the plunge, don't go "all in" on day one. Start small.
Step 1: Audit your failure points.
Identify the one process in your system that keeps breaking or leaving "zombie" data in your database. Don't migrate everything. Just migrate that one headache.
Step 2: Choose your flavor.
Do you want to write code or draw boxes?
- Code-heavy: Go with Temporal or Cadence.
- Visual-heavy: Go with Camunda or Kestra.
- Lightweight/Developer-centric: Check out Inngest or Hatchet (they are newer but gaining massive traction for being less "heavy" than the giants).
Step 3: Build a "Poison Pill" Strategy.
What happens when a workflow fails and can't be retried? You need a "Dead Letter Queue" or a manual intervention UI. An open source workflow engine doesn't magically fix bugs; it just gives you a better place to see them.
Step 4: Infrastructure Planning.
If you're using a database-backed engine, please, for the love of all things holy, give it its own database instance. Do not let your workflow engine's state-shuffling compete with your primary production app's queries.
The goal here isn't to have the coolest tech stack. It's to stop getting paged at 3:00 AM because a distributed transaction failed halfway through and left your data in an inconsistent state. A workflow engine is a tool for peace of mind, not just another layer of abstraction. Use it wisely, and it’s a superpower. Use it poorly, and you’ve just built a very expensive way to crash your servers.
Summary of Actions
- Define your "timeout" requirements before picking a tool.
- Choose Temporal if your team is comfortable with advanced distributed systems concepts.
- Choose Camunda if you need to show your progress to non-technical stakeholders.
- Avoid building your own engine from scratch using "status" columns in a SQL table; it never ends well once you hit scale.
- Check the license! Projects like Conductor (originally Netflix) have moved around between different "open" and "community" versions. Ensure your legal department won't have a heart attack in two years.