You’re staring at a wall of decimals. It looks like a code from a 1990s sci-fi movie, or maybe just a spreadsheet that someone forgot to format. Most students—and honestly, plenty of working professionals—see the z table normal distribution and immediately feel their eyes glaze over. It’s understandable. We live in an era of Python libraries and instant calculators where you can find a p-value in about three keystrokes.
So why are we still talking about this paper grid? Because understanding the z-table is basically like understanding the DNA of data. It’s the difference between blindly trusting an algorithm and actually knowing why a result is statistically significant.
Whether you’re trying to figure out if a marketing campaign actually worked or if a manufacturing process is spitting out too many defects, this table is your compass. It’s the bridge between a raw data point and a meaningful probability.
The Intuition Behind the Curve
Before you even touch the table, you have to visualize the bell. The Normal Distribution (or Gaussian distribution if you want to sound fancy at a dinner party) is everywhere. Height, IQ scores, the weight of newborn babies—they all tend to cluster around a middle average.
The z-score is just a way of asking, "How weird is this specific data point?"
✨ Don't miss: Copy Pasta: What It Actually Is and Why It Owns the Internet
If you have a z-score of 0, you’re perfectly average. You’re right in the thick of things. But if you have a z-score of 3.0? You’re an outlier. You’re the person who is 7 feet tall. You’re the ultra-rare event. The z table normal distribution translates that "weirdness" into a percentage. It tells you exactly how much of the population sits below or above that value.
Why We Standardize Things
Imagine comparing a test score out of 50 to a test score out of 100. It’s messy. To make sense of it, we use the formula:
$$z = \frac{x - \mu}{\sigma}$$
Here, $x$ is your value, $\mu$ is the mean, and $\sigma$ is the standard deviation. By doing this math, you’re stripping away the original units—be it inches, pounds, or dollars—and turning everything into "standard deviations from the mean." This is the "Standard Normal Distribution." It always has a mean of 0 and a standard deviation of 1.
Once you’ve converted your messy real-world data into a z-score, the table finally becomes useful.
Reading the Table Without Losing Your Mind
There isn't just "one" table, which is where most people get tripped up. Usually, you’re looking at a cumulative probability table. It shows the area to the left of your z-score.
Here is how you actually use it:
First, look at the left-hand column. This gives you the first two digits of your z-score (e.g., 1.4). Then, look at the top row. This gives you the hundredths place (e.g., .06). Where they meet in the middle is your probability.
If you find 1.4 in the column and .06 in the row, the intersection might show something like .9279. That means 92.79% of the data falls below that point. It’s that simple. Well, it’s simple once you realize the table is just a map.
Positive vs. Negative Z-Tables
Some textbooks split these into two pages. The negative table handles everything below the mean (z-scores like -1.5 or -2.1). The positive table handles everything above it.
If you only have a positive table, don't panic. Because the bell curve is perfectly symmetrical, the area to the left of -1.5 is the exact same as the area to the right of +1.5. You just have to do a little subtraction ($1 - \text{probability}$) to find what you need. It’s basically just spatial logic.
Real World: The Case of the Quality Control Crisis
Let’s look at a real example. Say you run a factory that produces lightbulbs. The average lifespan is 1,200 hours with a standard deviation of 50 hours. A customer complains that their bulb died at 1,050 hours.
Is that bulb a "lemon," or is it just a normal part of the distribution?
You calculate the z-score: $(1050 - 1200) / 50 = -3$.
When you check the z table normal distribution for -3.00, you’ll find a value around 0.0013. That means there is only a 0.13% chance of a bulb dying that early. In other words, out of 1,000 bulbs, only one or two should fail that fast. The customer is right; something went wrong in the factory that day. This isn't just math—it's evidence for a business decision.
Common Misconceptions That Mess People Up
People think the z-table works for everything. It doesn't.
If your sample size is tiny—let's say under 30—the normal distribution might not be your best friend. In those cases, experts like William Sealy Gosset (who wrote under the pen name "Student") developed the t-distribution. It’s like a bell curve but with "heavier tails" to account for the uncertainty of small samples.
Another mistake? Forgetting that the table usually measures the area to the left. If you want to know the probability of something being greater than your z-score, you have to subtract the table value from 1. If you forget this, your results will be the polar opposite of reality. It happens more often than you'd think in undergrad stats labs.
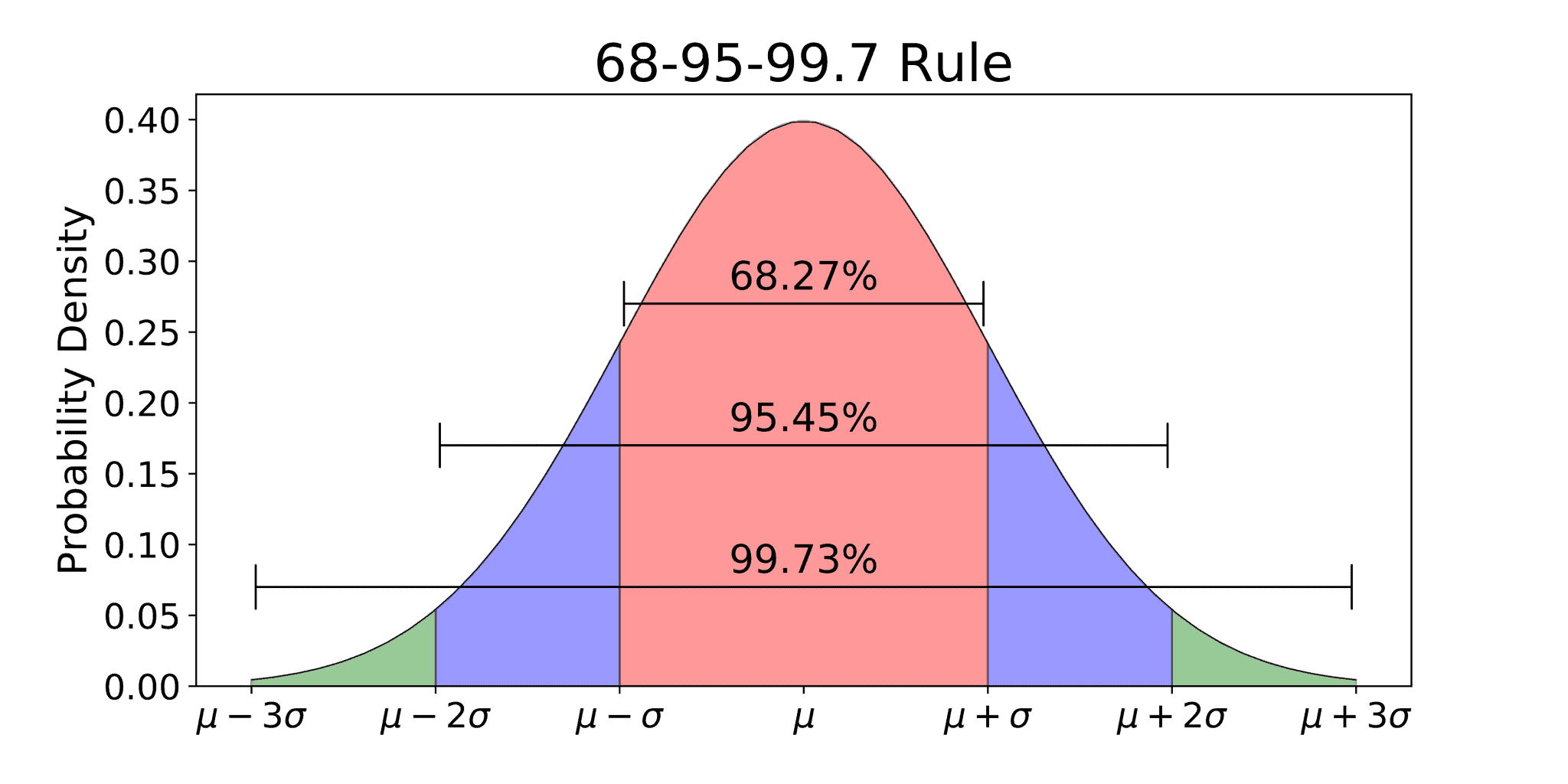
Nuance: The 68-95-99.7 Rule
You might have heard of the Empirical Rule. It’s a shorthand for the z-table.
- 68% of data is within 1 standard deviation.
- 95% is within 2.
- 99.7% is within 3.
This is why a z-score of 3 is such a big deal in "Six Sigma" business practices. If you’re at 3 standard deviations, you’re touching the very edge of what is expected. If you hit 6 standard deviations (Six Sigma), you’re looking at 3.4 defects per million opportunities. The z-table is the mathematical foundation for that entire corporate philosophy.
Why We Still Use Paper Tables in 2026
You might ask: "Why can't I just use =NORMSDIST() in Excel?"
You should. Honestly, you probably will. But the table teaches you the relationship between the numbers. When you use a software package, it’s a black box. You put a number in, a number comes out. When you use a table, you see how small changes in the z-score lead to massive changes in probability as you move toward the tails of the curve.
It builds a "number sense." It helps you spot when a computer output is obviously wrong because of a typo. It makes you a better skeptic of data.
Actionable Steps for Mastering the Z Table
Don't just memorize the table. Use it.
- Verify your distribution. Before using a z-table, make sure your data is actually normal. If it’s skewed (like income data often is), the z-table will give you wrong answers. Use a Q-Q plot or a Shapiro-Wilk test to check.
- Sketch the curve. Every single time you solve a problem, draw a quick bell curve on a scrap of paper. Shade the area you’re trying to find. This prevents the "left vs. right" subtraction errors that plague even experts.
- Practice the reverse lookup. Sometimes you know the percentage (e.g., "I want to find the top 5% of performers") and need the z-score. Find .9500 in the middle of the table and look outward to the headers to find the z-score (which is 1.645).
- Learn the critical values. There are a few z-scores you’ll use constantly in hypothesis testing. 1.645, 1.96, and 2.58 correspond to 90%, 95%, and 99% confidence levels. Memorizing these will save you hours over a semester or a career.
The z-table isn't an artifact; it's a visualization tool. It turns abstract randomness into something we can measure, predict, and control. Next time you see that wall of decimals, remember that it represents the predictable patterns of our chaotic world.