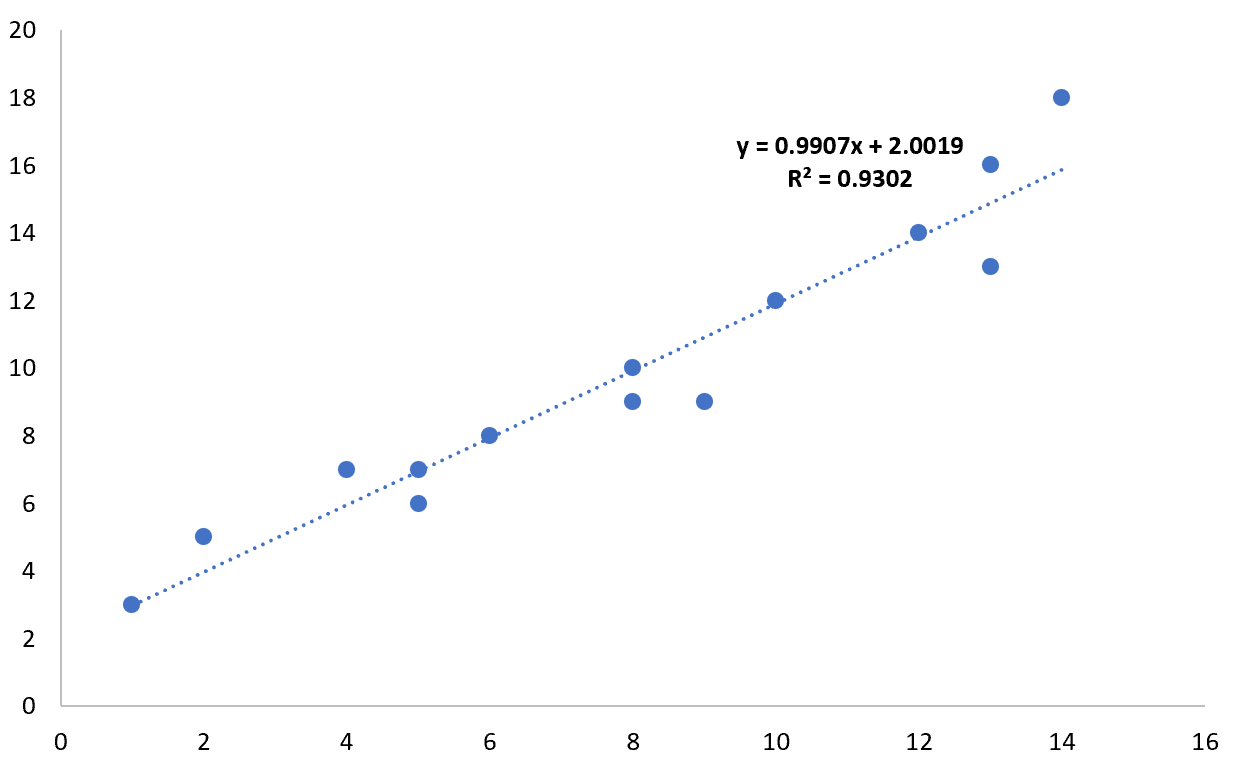
Ever looked at a chart and wondered if the two lines moving together actually mean anything? Or maybe you’ve seen a headline claiming a "strong link" between coffee and living until you're 100. Honestly, most of those claims live or die by a single number. That number is the r value in statistics.
It's officially called the Pearson Correlation Coefficient. Sounds fancy. It isn't, really.
🔗 Read more: The Real Gemini: How Google’s AI Actually Works and Why It Looks the Way It Does
Basically, it's just a way to put a number on how much two things "like" each other. If I eat more pizza, do I spend more money? If the temperature drops, do heater sales go up? The r value tells us if there’s a pattern. But here’s the kicker: people misuse this number constantly. They see a high r value and immediately assume one thing caused the other. It drives statisticians crazy.
What the r value in statistics actually measures
Let's get technical for a second, but keep it simple. The r value lives on a scale. It’s a strict scale. It goes from -1.0 to +1.0. That’s it. You’ll never see an r value of 5. If you do, someone’s math is broken.
When you have a +1.0, it’s a perfect positive correlation. Picture a diagonal line going up and to the right. Every time X goes up, Y goes up by a predictable amount. It’s beautiful. It’s rare. In the real world, things are messy. You're more likely to see something like 0.7 or 0.4.
Then you’ve got the negative side. This messes with people's heads. A -1.0 isn't "bad." It just means they have an inverse relationship. Think of it like a seesaw. When one side goes up, the other goes down. A classic example? The more you party, the lower your GPA might be. That’s a negative correlation. It’s still a strong relationship, just in the opposite direction.
And then there’s zero.
Zero is the "nothing to see here" number. If your r value is 0.0, there’s no linear relationship at all. It’s just a cloud of random dots on a graph. Like trying to find a correlation between your shoe size and how much you like the color blue.
The Math Behind the Curtain
I know, math can be a buzzkill. But you kind of need to know where this comes from to trust it. The formula looks like this:
$$r = \frac{\sum (x_i - \bar{x})(y_i - \bar{y})}{\sqrt{\sum (x_i - \bar{x})^2 \sum (y_i - \bar{y})^2}}$$
Don't panic.
You don't need to do this by hand anymore. Excel, Python, or even a basic TI-84 handles it in a heartbeat. Essentially, the top part of that fraction (the numerator) looks at how X and Y vary together. The bottom part (the denominator) looks at how they vary individually. By dividing them, we "normalize" the data. This is why the r value doesn't care if you're measuring in inches, miles, or lightyears. The result is always that same -1 to +1 scale.
Why "Strong" is a Relative Term
What counts as a "good" r value? Honestly, it depends on who you ask.
If you’re a physicist in a lab, an r value of 0.9 might be "okay" but a bit sloppy. They want precision. They want those atoms behaving exactly as predicted. But if you're a sociologist studying human behavior? You'd probably throw a party for a 0.5. Humans are chaotic. We don't follow neat lines. If a researcher finds a 0.6 correlation between childhood environment and career success, that’s a massive discovery.
Context is everything.
You’ve also got to watch out for "p-values" lurking in the shadows. An r value tells you the strength of the relationship, but the p-value tells you if that relationship is just a fluke. You could find a perfect 1.0 correlation between two random things just by sheer luck if your sample size is tiny. If I flip a coin twice and get heads both times, I have a "perfect correlation" between my flips and heads. But it doesn't mean anything. You need a decent sample size—think 30, 100, or thousands of data points—to make that r value worth the paper it’s printed on.
📖 Related: Facebook Cover Photo Black: Why This Simple Aesthetic Actually Works
The Correlation vs. Causation Trap
We have to talk about it. It’s the biggest mistake in data analysis.
Just because the r value in statistics shows a strong link doesn't mean X caused Y. There’s a famous, somewhat morbid example involving ice cream and drowning deaths. If you plot them on a graph, they have a very high positive r value. When ice cream sales go up, drownings go up.
Does ice cream make people sink? No.
There’s a "lurking variable" here: Summer. When it's hot, people buy ice cream. When it's hot, people go swimming. Heat causes both. The ice cream and the drowning are just along for the ride. This is why you can’t just look at a correlation and claim you’ve solved a mystery. You have to rule out the "hidden" factors first.
Limitations: Where r Fails
The r value is great, but it’s not a magic wand. It has a major weakness: it only sees straight lines. It’s built for "linear" relationships.
Imagine a relationship that looks like a U-shape. Maybe it’s the relationship between anxiety and performance. A little anxiety helps you focus (performance goes up). But too much anxiety makes you freeze (performance goes down). If you ran an r value on that U-shaped data, it would probably come out close to zero. The r value would tell you there’s no relationship, even though there clearly is one. It’s just not a straight one.
Outliers are another headache. One weird data point can ruin everything. Imagine you’re measuring the correlation between height and weight in a classroom. Then, for some reason, a 7-foot-tall NBA player walks in who happens to be extremely thin. That one "outlier" can tug on the r value like a leash, making the relationship look much weaker or stronger than it actually is for the rest of the group.
Real-World Examples That Matter
In the business world, the r value is everywhere.
Marketing teams use it to see if their ad spend actually correlates with sales. If they spend $10k on Instagram ads and see an r value of 0.8 with their weekend revenue, they're probably going to keep spending. But if that r value is 0.1? They’re essentially throwing money into a black hole.
In healthcare, researchers use it to identify risk factors. They might look at the correlation between daily step counts and resting heart rate. A negative correlation there (more steps, lower heart rate) is exactly what they want to see. It helps form the basis for public health advice, even before they’ve done the more expensive, controlled clinical trials to prove causation.
How to use this knowledge right now
So, you’re looking at some data. Maybe it’s for a work report or a school project. How do you handle the r value like a pro?
First, visualize it. Seriously. Never look at the r value alone. Make a scatter plot. If the dots look like a swarm of bees, a "strong" r value is probably a lie or an outlier. If you see a curve, the r value isn't the right tool for the job.
Second, check your sample size. If you’re looking at five people, the r value is basically gossip. You need more data.
✨ Don't miss: Verizon Wireless Down Detector: Why Your Signal Just Vanished and What to Do Next
Third, be skeptical. Always ask, "What else could be causing this?" If you see a correlation between umbrellas and rain, don't assume the umbrellas are making the sky leak.
The r value in statistics is a tool, not a conclusion. It’s a way to start a conversation, not end it. Use it to find patterns, then use your brain to figure out if those patterns actually matter.
Your Next Steps
- Run a Scatter Plot: Before calculating r, plot your data in Excel or Google Sheets. Look for those straight-line patterns or weird outliers that might skew your result.
- Calculate the Coefficient of Determination ($r^2$): Square your r value. If your $r$ is 0.7, $r^2$ is 0.49. This tells you that 49% of the variance in one variable is explained by the other. It's often a more honest way to look at the "strength" of a relationship.
- Investigate Outliers: If you find a data point that sits far away from the rest, look into why. Was it a typing error? A one-time event? Decide whether to keep it or remove it based on whether it represents the "real" world you're trying to measure.
- Verify Significance: Use a p-value calculator alongside your r value to ensure your findings aren't just a statistical fluke due to a small sample size.