You've probably typed it a thousand times. It’s the muscle memory of the Python world. You clone a repo, you create a virtual environment, and then you fire off pip install -r requirements.txt without even thinking about what's actually happening under the hood. It’s the basic "I want this code to work" command.
But honestly? Most people use it wrong. Or at least, they use it in a way that’s eventually going to cause a massive headache when their production server decides to spontaneously combust because a minor dependency updated at 3:00 AM.
📖 Related: Why Earth is the Centre of the Universe to the Human Mind
The magic and the mess of pip install -r requirements.txt
The -r flag stands for "recursive." It’s telling pip, "Hey, don't just look for a package name; go look inside this file and do what it says." It sounds simple. It is simple.
The problem is that the requirements.txt file is often a dumping ground.
When you run pip install -r requirements.txt, pip starts at the top of the list and begins a complex dance called dependency resolution. It tries to find versions of every package that play nice together. If you have Package A that needs Package C version 1.0, and Package B that needs Package C version 2.0, pip is going to have a very bad day. And so are you.
I’ve seen developers lose entire weekends to "dependency hell" just because one person on the team updated their local environment and forgot to pin their versions. It’s a classic. You think you’re installing the same environment as your coworker, but you’re actually installing a ticking time bomb.
Why pinning is non-negotiable
If your file just says requests, you are playing Russian Roulette with your code.
Always pin. Seriously.
A "loose" requirement like requests tells pip to grab the latest version. If the Requests team releases a breaking change tomorrow, your deployment will fail. Instead, you should see requests==2.31.0. That double equals sign is your best friend. It guarantees that the code you wrote today will still run on a different machine six months from now.
Some folks prefer the "compatible release" operator, ~=. For example, requests~=2.31.0 allows updates that are 2.31.1 or 2.31.2 but won't jump to 2.32.0. It’s a middle ground. Kinda useful, but I still prefer exact pinning for production.
Creating the file without the junk
Most people create their requirements file by running pip freeze > requirements.txt.
Stop doing that.
pip freeze dumps everything in your current environment into that file. If you’ve been experimenting with unrelated libraries like pandas or pytest in that same environment, they all get shoved into the requirements. This creates massive, bloated Docker images and slows down your CI/CD pipelines.
Instead, use a tool like pip-reqs or, better yet, manage your requirements manually. Only put the top-level dependencies—the ones your code actually imports—into your primary list. Let the package manager handle the sub-dependencies.
The hidden power of the -e flag
Sometimes you aren't just installing stuff from PyPI. Sometimes you’re working on a local library or a fork of a project on GitHub.
You can actually put -e . or -e git+https://github.com/user/repo.git#egg=pkg inside your requirements.txt. The -e stands for "editable." This is huge for development. It means if you change the code in that local library, the changes are immediately reflected in your main project without having to reinstall anything.
It’s one of those features that makes pip install -r requirements.txt feel less like a static installer and more like a dynamic environment orchestrator.
Environment variables and secret sources
Did you know you can use environment variables inside the file?
If you’re pulling from a private GitHub repo or a private Artifactory instance, you don't want to hardcode your tokens. You can write something like:git+https://${GITHUB_TOKEN}@github.com/org/repo.git
When you run pip install -r requirements.txt, pip will look for that GITHUB_TOKEN in your system's environment variables. It’s a clean way to keep secrets out of your git history.
When pip install -r requirements.txt isn't enough
Let’s be real. requirements.txt is the "old school" way.
It doesn't handle "build-time" vs "run-time" dependencies very well. It doesn't have a built-in lockfile (unless you count the frozen file itself, which is messy).
This is why tools like Poetry and PDM have exploded in popularity. They use pyproject.toml, which is the new standard (PEP 518). They separate your direct dependencies from the "locked" versions of every single sub-dependency.
If you're starting a brand new, enterprise-grade project, you might want to skip the .txt file entirely and go with Poetry. But for scripts, small apps, or existing legacy projects, pip install -r requirements.txt is still the king. It’s universal. Every server, every CI runner, and every developer knows how to handle it.
Dealing with OS-level dependencies
One thing pip will never solve for you is the stuff outside of Python.
If you’re installing psycopg2 for PostgreSQL or Pillow for image processing, you need C libraries installed on your actual operating system (like libpq-dev or libjpeg-dev).
Running pip install -r requirements.txt and seeing a giant wall of red text usually means you’re missing a system header. This is where Docker saves lives. By defining your OS dependencies in a Dockerfile and then running the pip command, you create a truly reproducible environment.
Real-world troubleshooting
If you're stuck, try these steps.
First, check your pip version. Old versions of pip have terrible dependency resolvers. Run pip install --upgrade pip before you do anything else.
Second, use a virtual environment. Never, ever run pip install -r requirements.txt on your global system Python. You will break your operating system's tools. Use python -m venv venv and activate it first.
Third, if things are still weird, try the --no-cache-dir flag. Sometimes pip gets confused by a corrupted cached version of a package. Clearing the cache forces it to download a fresh copy.
Actionable steps for your workflow
To get the most out of your dependency management, stop treating the requirements file as a checklist and start treating it as code.
📖 Related: The Spotify Account and Hulu Bundle: Why It’s Getting Harder to Find
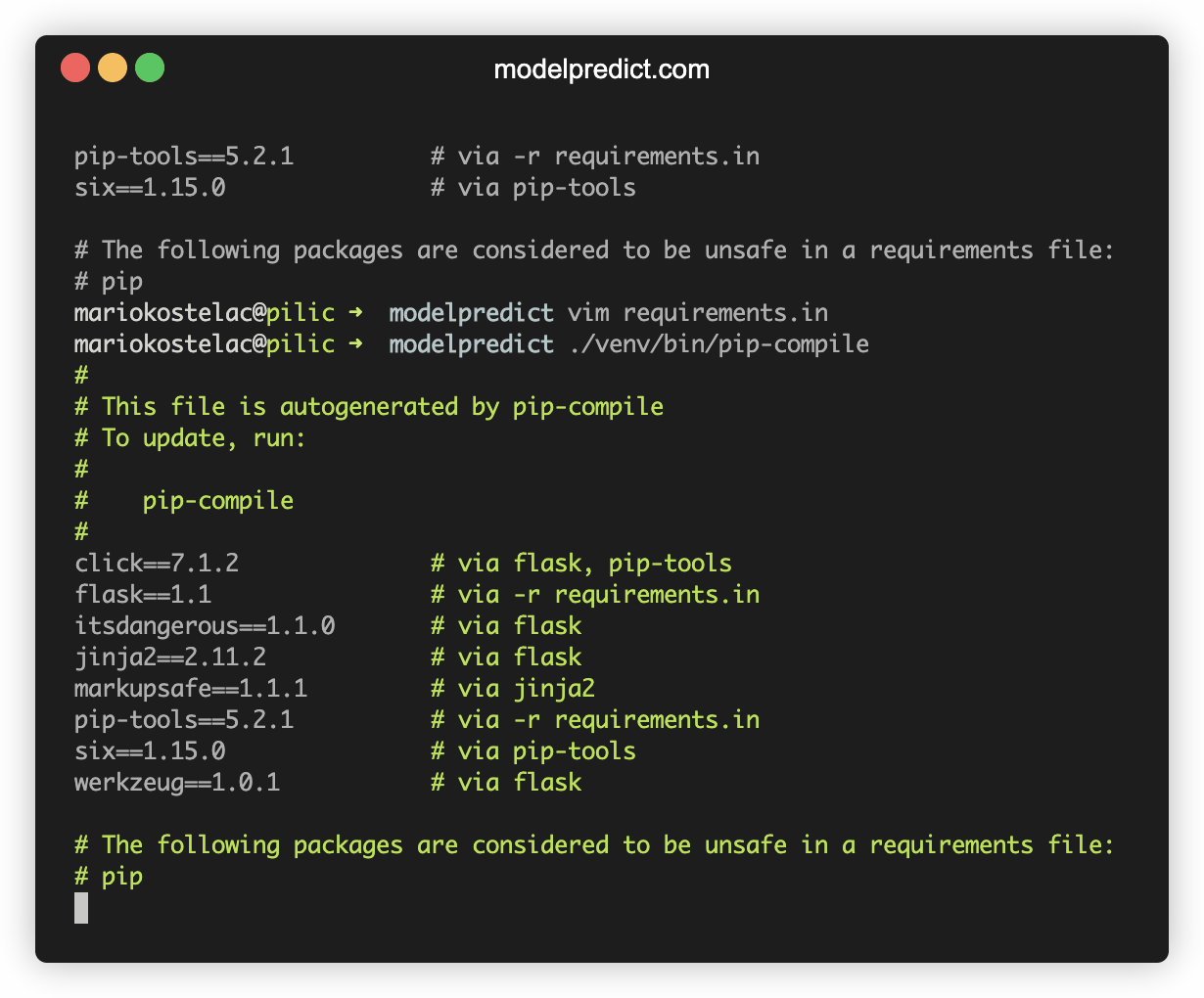
- Audit your current file. Run
pip-auditto see if any of the versions you've pinned have known security vulnerabilities. It’s a free tool and it’s surprisingly thorough. - Move to a "layered" approach. Create a
requirements.infile with your main packages (e.g.,flask,sqlalchemy) and usepip-compile(from thepip-toolspackage) to generate the actualrequirements.txt. This gives you the best of both worlds: a readable list of what you need and a locked list of what actually gets installed. - Use hashes for security. If you’re in a high-security environment, use
--generate-hasheswithpip-compile. This adds a checksum to every package in your file, ensuring that nobody can tamper with the files on PyPI and inject malicious code into your build. - Check for "ghost" dependencies. Every few months, go through your file and see if you’re still using everything. Unused packages increase your attack surface and make your deployments heavier than they need to be.
The humble pip install -r requirements.txt command is incredibly robust, but its simplicity is deceptive. Treat it with a bit of respect, pin your versions, and keep your environments isolated, and you'll avoid 90% of the "it works on my machine" bugs that plague Python development.