Data engineering used to be the bottleneck that killed every promising machine learning project. You’ve probably seen it yourself: a data scientist builds a brilliant model in a notebook using some Python magic, but the moment they try to move it into production, the whole thing falls apart. The features that worked in training don't exist in the live environment. Or worse, the math is slightly different. This "training-serving skew" is a silent killer. That’s exactly why the intersection of Databricks Tecton ML Tecton has become such a massive talking point for engineering teams trying to actually get ROI out of their AI investments.
It’s about the "feature store."
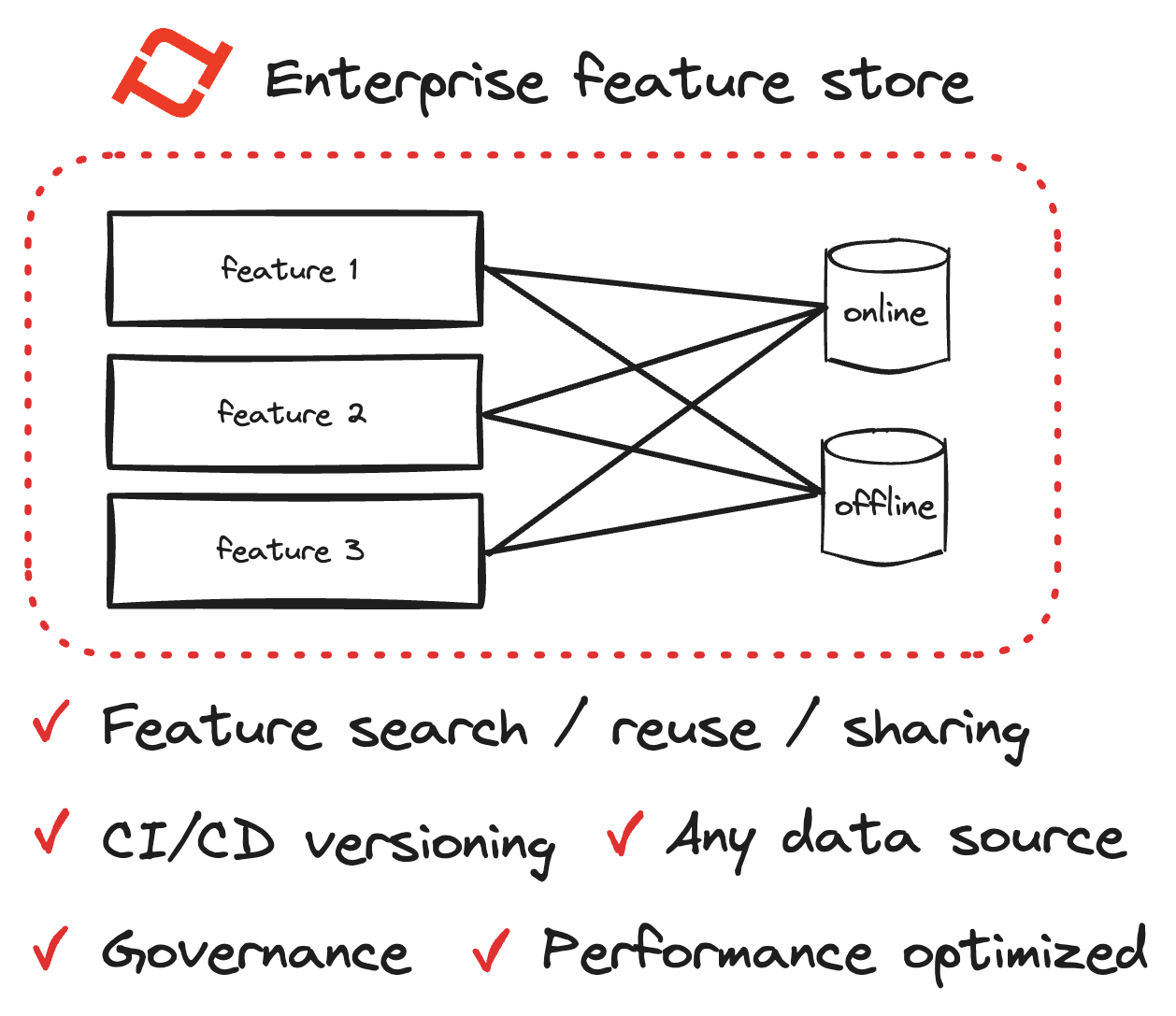
If you aren't familiar, a feature store is basically the interface between your raw data and your machine learning models. It’s where the "features"—those specific variables like average purchase value over the last 30 days—live. When you combine the massive processing power of Databricks with the specialized orchestration of Tecton, you’re basically building a high-speed pipeline that ensures your model is never "hungry" for fresh data.
The Reality of Running Tecton on Databricks
Most people think they can just build their own feature store using a few SQL tables and a prayer. They’re wrong.
Databricks is phenomenal at the heavy lifting. It’s the engine. It handles the Spark jobs, the Delta Lake storage, and the massive compute requirements that come with processing petabytes of logs. But Databricks isn't inherently a "feature platform" in the way Tecton is. Tecton acts as the brain. It sits on top of Databricks, using the compute power of the Lakehouse to transform raw data into ML-ready features.
The magic happens in the workflow. Tecton defines features as code. You write a snippet of Python or SQL, and Tecton manages the rest. It tells Databricks when to run the jobs to update those features. It then makes those features available for offline training (the "big data" side) and online serving (the "low latency" side) simultaneously.
Honestly, the split between these two environments is where most companies fail. You have one team writing Spark jobs for the warehouse and another team writing C++ or Java for the production API. They never match. By using Databricks Tecton ML Tecton patterns, you write the logic once. Tecton ensures the Spark job on Databricks produces the exact same result as the real-time lookup in the production environment.
Why ML Teams are Moving Away from Homemade Solutions
I’ve talked to engineers at companies like HelloFresh and Progressive who have dealt with this. They realized early on that maintaining a home-grown feature store is a full-time job for five senior engineers. Nobody wants to be in the business of maintaining infrastructure; they want to be in the business of shipping models.
The "ML" in Databricks Tecton ML Tecton signifies the operationalization of these features. We aren't just talking about storage. We are talking about:
- Feature Lineage: Knowing exactly which version of the data went into which version of the model.
- Point-in-time Correctness: This is a big one. If you are training a model to predict fraud, you can't use data from after the fraud happened to train the model. Tecton handles the complex "as-of" joins so you don't leak future data into the past.
- Declarative Frameworks: You describe what the feature is, not how to move the bits.
It's kind of a relief for the data scientists. They don't have to become DevOps experts. They stay in their lane, and the infrastructure just... works.
How the Architecture Actually Fits Together
Think of your Databricks environment as the source of truth. You’ve got your Bronze, Silver, and Gold tables in Delta Lake. Tecton hooks into these.
When a feature is defined in Tecton, it triggers a Spark job on a Databricks cluster. That job calculates the values and stores them. For training, Tecton pulls directly from the Delta tables. For real-time serving—say, a recommendation engine on a website—Tecton can push those same features into a low-latency store like DynamoDB or Redis.
The beauty here is that Tecton manages the "glue." It handles the scheduling, the monitoring, and the data quality checks. If the Databricks job fails and the features start to go stale, Tecton alerts you. Without this, your model would just keep making predictions on old data, and your conversion rates would tank without anyone knowing why.
Common Pitfalls and the "Gotchas"
It isn't all sunshine and automated pipelines.
Cost is a real factor. If you aren't careful, running constant Spark jobs on Databricks to refresh features every five minutes will burn through your budget. You have to be smart about "materialization" intervals. Does that feature really need to be updated every minute? Probably not. Maybe once an hour is fine.
Another issue is organizational. Using Databricks Tecton ML Tecton requires the data engineering team and the ML team to actually talk to each other. Tecton forces a "features as code" workflow, which means using Git and CI/CD. If your data scientists are used to just hacking away in unversioned notebooks, this is going to be a culture shock.
But honestly? It’s a necessary shock.
🔗 Read more: Why Some Songs Are Not Available on Apple Music (and How to Find Them)
The "Wild West" era of ML is over. The companies winning right now are the ones who have treated their data pipelines with the same rigor as their software code.
Real-World Impact of Unified Feature Platforms
Let's look at a real scenario. Imagine a ride-sharing app. They need to predict the "estimated time of arrival" (ETA).
To do this well, the model needs to know:
- The historical average speed on that road (Batch data in Databricks).
- The current traffic conditions (Streaming data via Kafka/Spark Streaming).
- The specific driver's recent performance (Real-time data).
Tecton orchestrates this. It pulls the historical stuff from Databricks, joins it with the streaming data, and serves it up in milliseconds. If they tried to do this manually, the "historical" data would likely be formatted differently than the "live" data, leading to the model being wildly inaccurate.
By unifying the stack, the "ML" part of the equation becomes much more predictable. You stop guessing why the model is underperforming in the real world.
Actionable Steps for Implementation
If you are looking to integrate these tools, don't try to boil the ocean.
First, identify your most "expensive" feature. Not expensive in terms of money, but expensive in terms of engineering time. Which feature is constantly breaking? Which one causes the most arguments between the data scientists and the engineers? Start there.
Second, audit your Databricks clusters. Tecton is going to be spinning up compute to run these transformations. Make sure you have appropriate tagging and cost controls in place on the Databricks side so you can see exactly what Tecton is costing you versus your other workloads.
Third, move to a "Feature-First" mindset. Before a single line of model code is written, define the features in Tecton. This forces the team to ensure the data actually exists and is accessible before they waste weeks training a model on "ghost data" that can never be replicated in production.
Finally, lean into the "as-code" philosophy. Store your Tecton feature definitions in the same repository as your model training code. This ensures that when you update a feature's logic, the model and the infrastructure stay in perfect sync.
The combination of Databricks Tecton ML Tecton isn't just a tech stack change; it's a shift toward actual Machine Learning Operations (MLOps) maturity. It takes the "magic" out of the process and replaces it with a reliable, repeatable factory for intelligence. Stop building custom scrapers and manual ETLs for your models. Use the platform designed to handle the scale.