Ever looked at a weather forecast that said the average temperature for the month is 70 degrees, only to spend half the time shivering at 50 and the other half sweating at 90? That’s the problem with averages. They hide the chaos. If you want to actually understand what’s happening in a dataset—whether it's stock market swings, battery life in new iPhones, or how many points LeBron might score tonight—you have to look at variance in statistics.
Variance is basically a measure of "spread." It tells you how far the numbers in a list are huddling together or sprinting away from the mean. Honestly, without it, the mean is just a lonely point in space with no context. You’ve probably heard people talk about "volatility" in finance or "consistency" in sports. They’re just using fancy synonyms for variance.
What Is the Variance in Statistics Anyway?
Let’s get technical for a second, but keep it grounded. In a formal sense, variance is the average of the squared differences from the mean. It sounds like a mouthful, but think of it as the "mathematical vibration" of your data. If the variance is zero, every single number in your set is identical. There’s no variety. No spice. As soon as one number moves, the variance starts to climb.
Mathematically, we represent it as $\sigma^2$ for a population or $s^2$ for a sample. The formula looks like this:
$$\sigma^2 = \frac{\sum (X - \mu)^2}{N}$$
You take each number ($X$), subtract the average ($\mu$), square that result (to make sure negative numbers don't cancel out the positive ones), and then average those squares. Why square them? Because if you just added up the differences, they’d sum to zero. The math would just eat itself. Squaring gives every "error" or "distance" a positive value, emphasizing how much things are actually drifting.
The Real-World Drama of High Variance
Imagine two coffee shops. At Shop A, every latte takes exactly 4 minutes to make. The variance is zero. At Shop B, the average wait time is also 4 minutes, but sometimes you get your drink in 30 seconds and sometimes you’re stuck there for 15 minutes while the barista fixes the steam wand.
Shop B has high variance.
Even though the "average" is the same, your experience at Shop B is unpredictable. This is why manufacturing giants like Motorola and GE obsessed over "Six Sigma" back in the day. They weren't just trying to be fast; they were trying to kill variance. In a factory, variance is the enemy. It's the reason one car door fits perfectly and the next one rattles like a tin can.
Why We Square the Numbers (The "Why" Matters)
Most people ask: "Why not just use absolute values?" You could. That would be the Mean Absolute Deviation. But the giants of statistics—guys like Ronald Fisher and Karl Pearson—preferred squaring.
Squaring does something specific: it penalizes outliers.
If a data point is 2 units away from the mean, its "penalty" is 4. If it’s 10 units away, its penalty jumps to 100. Variance screams when it sees an outlier. This makes it incredibly sensitive, which is both a blessing and a curse. If you have one weird data point in your study, your variance will explode, potentially masking the trend of the rest of the group.
Sample vs. Population: The N-1 Trick
Here is where it gets slightly annoying. If you’re calculating variance for an entire population (every single person in a country), you divide by $N$. But if you’re just using a sample (100 people to represent the country), you divide by $n-1$. This is called Bessel’s Correction.
Why? Because samples usually underestimate how much variety is actually out there in the real world. Dividing by a smaller number ($n-1$) makes the variance slightly larger, which is a way of "padding" the estimate to be more accurate. It’s a bit of a statistical fudge factor, but it works.
📖 Related: Finding a MacBook Pro 15 Case That Actually Fits Your Specific Model
Variance vs. Standard Deviation: The Identity Crisis
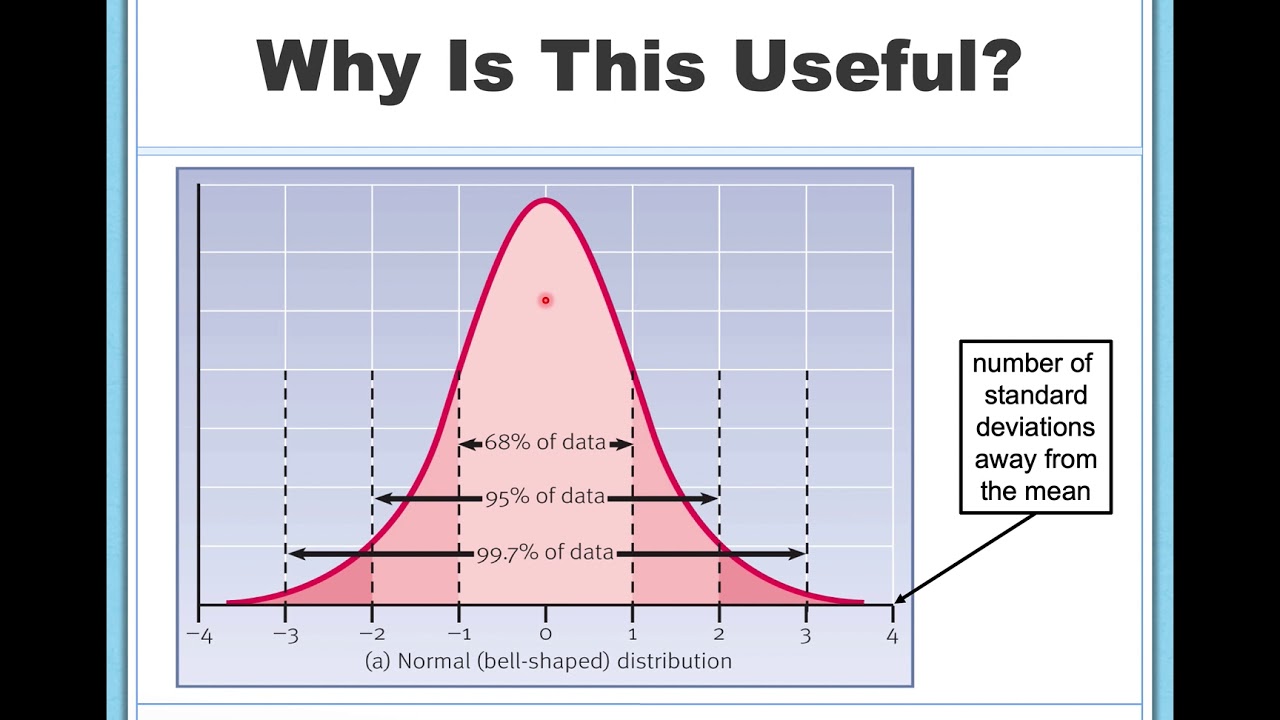
You can’t talk about variance without mentioning its more popular sibling, Standard Deviation. Since variance is measured in "squared units" (like "square dollars" or "square kilograms," which make no sense to the human brain), we take the square root of it to get back to the original units.
- Variance: The engine under the hood. It’s what you use for the heavy lifting in math and probability theory.
- Standard Deviation: The speedometer. It’s what you actually tell your boss or put in a news report because it’s in units people understand.
If the variance of house prices in a neighborhood is 1,000,000 square dollars, no one knows what that means. But if you take the square root and say the standard deviation is $1,000, you’re talking a language humans understand.
The Dark Side: When Variance Misleads
Context is everything. You might see a high variance and think, "Wow, this data is all over the place!" But maybe you’re just looking at a bimodal distribution—two different groups mixed together.
Think about heights in a gym. If you measure everyone at once, the variance is huge. But if you separate the toddlers in the daycare center from the NBA players on the court, the variance within each group shrinks drastically. Sometimes high variance isn't a sign of "messy" data; it's a sign that you’re accidentally mixing two different stories into one graph.
The "Risk" Factor in Finance
In the world of investing, variance is the literal definition of risk. When Harry Markowitz developed Modern Portfolio Theory (which won a Nobel Prize, by the way), he used variance to represent the volatility of an asset.
An investment with low variance is a "safe" bet—like a government bond. It doesn't move much. An investment with high variance—like a startup stock or a crypto coin—is a rollercoaster. You might end up on the moon, or you might end up in the dirt. Investors use variance to calculate the Sharpe Ratio, which basically asks: "Is the extra heart-attack-inducing variance of this stock actually worth the extra profit?"
How to Actually Use This
If you’re analyzing data at work or even just looking at your own spending habits, don't stop at the average. Look at the spread.
- Calculate the Mean: Find your average.
- Find the Deviations: See how far each point is from that average.
- Square Them: Get rid of the negatives.
- Average the Squares: That’s your variance.
- Interpret: If your variance is growing over time (say, in your monthly grocery bills), your habits are becoming less predictable.
Moving Beyond the Mean
Standardized testing is another great example. If two schools both have an average SAT score of 1200, you might think they're identical. But if School A has a low variance, it means almost every student is scoring right around 1200. If School B has a high variance, it means they have some geniuses scoring 1600 and some students struggling at 800.
Those are two very different schools requiring two very different sets of resources. The average tells you nothing about the struggle or the excellence happening at the edges.
Actionable Next Steps
To truly master the concept of variance in statistics, you need to see it in action. Stop looking at single-number summaries.
- Audit your datasets: Next time you see an "average" reported in a news article or a business meeting, ask for the standard deviation or the range.
- Visualize the Spread: Use a box plot or a histogram. A picture of variance is worth a thousand calculations.
- Check for Outliers: Before calculating variance, look for "black swans"—those weird data points that don't belong. They will tilt your variance and give you a false sense of how much "normal" variation exists.
- Use Variance for Decision Making: If you’re choosing between two processes, and both have the same average outcome, always pick the one with the lower variance. It’s more reliable, easier to plan for, and way less stressful.
Understanding variance is the difference between being a casual observer and actually knowing how the world works. It's the measure of uncertainty, and in a world that's increasingly data-driven, uncertainty is the only thing we can be sure of.