In 2015, a team from the University of Freiburg changed how we see medical images. Literally. Before Olaf Ronneberger, Philipp Fischer, and Thomas Brox released their paper on U-Net: convolutional networks for biomedical image segmentation, the world of computer vision was obsessed with classification. Everyone wanted to know if a picture contained a cat or a dog. But in medicine? Knowing there is a tumor "somewhere" in an MRI is useless. You need to know exactly where the boundaries are. You need pixels.
The U-Net architecture didn't just provide a solution; it became the industry standard. Even now, with all the hype around Transformers and Attention mechanisms, if you walk into a lab doing actual clinical research, you're going to find a U-Net variant running the show. It’s elegant. It’s fast. And honestly, it’s one of the few deep learning architectures that actually works when you don't have a billion labeled images.
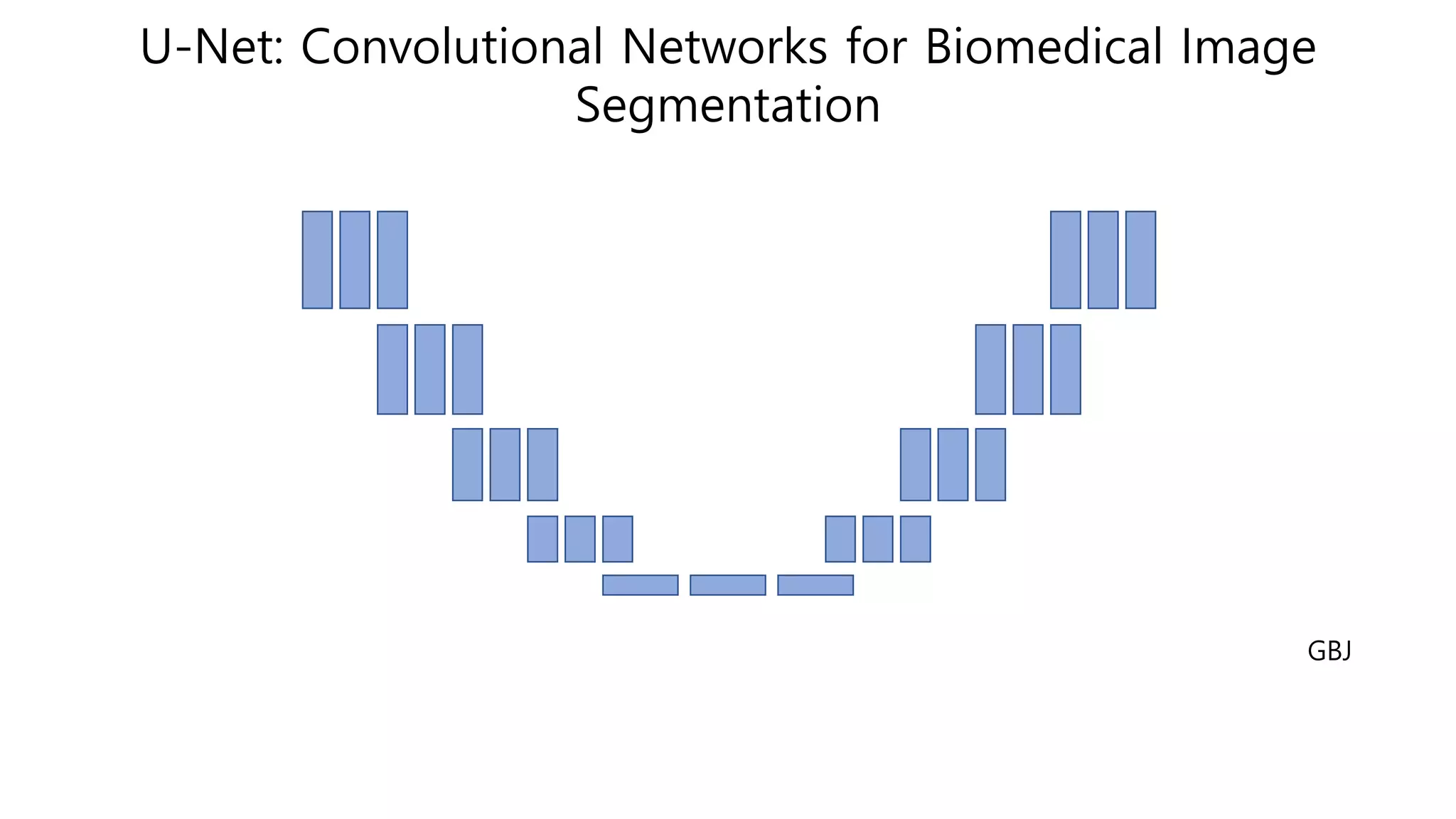
The Shape of Success: Why the "U" Actually Matters
Most neural networks are like a funnel. They take a big image, crunch it down, extract features, and give you a single label at the end. That’s great for identifying a face. It’s terrible for mapping a lung.
The U-Net architecture is shaped like a—you guessed it—letter "U." On the left side, you have the contracting path. This is the "encoder." It looks like a typical convolutional network. It takes the image and repeatedly applies $3 \times 3$ convolutions followed by $2 \times 2$ max pooling. Every time it does this, it loses spatial information but gains "what" information. It learns that a certain pattern of pixels represents a cell wall, but it starts to lose track of exactly where that cell wall was in the original 512x512 scan.
This is where the magic happens.
✨ Don't miss: OpenGL Error 1014: Why Your Graphics Card is Screaming at You
Instead of just stopping there, Ronneberger and his team built an expansive path on the right side. This "decoder" upsamples the feature maps. But upsampling is blurry. To fix the blur, they added "skip connections." These take the high-resolution features from the left side and crop-and-paste them directly onto the right side. It’s like giving the network a cheat sheet. It says, "Hey, I know you’re trying to reconstruct this image, so here’s exactly what the edges looked like before we shrunk them."
This symmetry allows the network to combine the "context" (the big picture) with the "localization" (the precise pixel coordinates). It’s why the output is a high-resolution map where every single pixel is classified. That is the essence of U-Net: convolutional networks for biomedical image segmentation.
Data Scarcity is the Real Enemy
In the tech world, we’re used to Big Data. Google and Meta have trillions of images. In medicine, you're lucky if a radiologist has time to hand-annotate 30 slices of a kidney. It's a nightmare.
Deep learning usually hates small datasets. It overfits. It gets lazy.
U-Net handles this through aggressive data augmentation. Since biological structures are somewhat elastic, the authors used elastic deformations. Think of it like taking a picture of a cell on a piece of rubber and stretching it in different directions. The network learns that a cell is still a cell even if it's squished or rotated. This trick allowed them to win the ISBI cell tracking challenge by a landslide, even when training data was incredibly sparse.
How U-Net Solved the "Touching Cells" Problem
One thing people often forget about the original U-Net paper is the weighted loss map. If you've ever looked at a slide of densely packed cells, you know they often touch. For a computer, distinguishing between two cells that are pressed against each other is incredibly hard. They just look like one big blob.
The researchers introduced a specific weight loss function. They basically told the network: "If you mess up the tiny gap between two touching cells, I'm going to penalize you way harder than if you mess up a pixel in the middle of the cell."
By forcing the network to focus on those thin borders, they achieved a level of separation that previous methods couldn't touch. It wasn't just about finding the object; it was about finding the boundaries of the object.
The Evolution: From 2D to 3D and Beyond
The original paper was focused on 2D slices. But humans are 3D.
✨ Don't miss: How to Master the Distance Calculator Google Map Feature for Precise Planning
Pretty quickly, the community realized that a 3D U-Net was the logical next step. Instead of $2 \times 2$ pooling, you use $2 \times 2 \times 2$. This allows the network to understand volumetric data like CT scans or MRI stacks. If you see a vessel in slice 10, the network knows it should probably still be there in slice 11.
Then came the variants. You’ve probably heard of some:
- Attention U-Net: Uses attention gates to focus on specific regions of interest.
- Res-UNet: Adds residual connections to help the gradient flow in very deep versions.
- UNet++: A nested version that tries to bridge the semantic gap between the encoder and decoder even more effectively.
Every time someone tries to "kill" the U-Net with a newer, flashier architecture, someone else just adds a new module to the U-Net and it takes the crown back. It's the "Old Reliable" of the medical AI world.
Why Transformers Haven't Replaced It Yet
Vision Transformers (ViTs) are the big thing right now. They are great at understanding long-range dependencies. They "see" the relationship between a pixel in the top-left and one in the bottom-right better than a convolution ever could.
However, Transformers are data-hungry. They are also computationally expensive.
In a clinical setting, you often need results fast, and you're working on specialized hardware that might not be a cluster of A100s. The U-Net's inductive bias—the assumption that nearby pixels are related—is actually a huge advantage in medical imaging. Anatomy follows rules. Your liver isn't going to suddenly teleport to your shoulder. The local focus of convolutions actually mirrors the physical reality of the human body.
Most modern researchers are now building "TransUNets"—hybrid models that use a Transformer for the bottleneck (the bottom of the U) but keep the convolutional U-Net structure for the high-res edges. It’s the best of both worlds.
Practical Realities: Implementing U-Net Today
If you’re looking to actually use U-Net: convolutional networks for biomedical image segmentation, don't start from scratch. Honestly.
The library segmentation_models for Keras or Monai for PyTorch (which is specifically built for medical AI) are the go-tos. Monai is particularly impressive because it handles the weird file formats radiologists use, like DICOM and NIfTI, which are a total pain to process manually.
One thing to watch out for is the "bottleneck" size. If you make the bottom of the U too small, you lose too much information. If you keep it too large, your GPU will run out of memory before you finish the first epoch. It’s a balancing act.
Also, remember the preprocessing. U-Net is sensitive to the scale of input values. If your MRI intensities range from 0 to 4000, you need to normalize them. Most people use Z-score normalization or simple min-max scaling. If you don't, the network will spend the first ten hours of training just trying to figure out why the numbers are so big.
The Limitations Nobody Admits
It's not perfect. U-Net can be "hallucination-prone" if the training data is biased. If a network only sees healthy lungs, it might try to "heal" a lung with a nodule by simply not segmenting it.
There's also the issue of "Over-fitting to the Dataset." A U-Net trained on scans from a GE machine might perform poorly on scans from a Siemens machine because the noise patterns are different. This is called "domain shift," and it's the biggest hurdle to getting these models into actual hospitals.
📖 Related: AI Education Policy News: Why Schools are Scrapping the Ban and Getting Real
Actionable Steps for Implementation
If you are a developer or researcher looking to leverage this architecture:
- Start with MONAI: If your data is medical, don't use generic CV libraries. MONAI has pre-built U-Net architectures that are optimized for 3D medical volumes.
- Prioritize the Skip Connections: When customizing the network, ensure your skip connections are correctly concatenating features. This is where the localization power lives.
- Use Heavy Augmentation: Use
AlbumentationsorTorchvisionto apply non-linear transformations. Specifically, look into elastic transforms; they simulate the squishy nature of human tissue. - Weighted Cross-Entropy: If your target (like a small tumor) only takes up 1% of the image, use a weighted loss function. Otherwise, the network will learn that it can get 99% accuracy by just predicting "nothing" for every pixel.
- Evaluate with Dice Coefficient: Don't use standard accuracy. Use the Dice Similarity Coefficient (DSC) or Intersection over Union (IoU). These metrics actually tell you how well the predicted mask overlaps with the ground truth.
The U-Net isn't just a paper from 2015. It's a foundational tool that proved deep learning could be precise, not just predictive. Whether you're segmenting satellite imagery or looking for microscopic anomalies in a biopsy, the U-shape remains the most efficient way to map the world.
To move forward, focus on domain generalization. A model that works in one hospital is a tool; a model that works in every hospital is a breakthrough. Start by testing your U-Net on out-of-distribution data as early as possible to identify where the "U" begins to break.