You probably checked your bank balance today. Or maybe you bought a plane ticket, scrolled through a messy inventory list at work, or just swiped right on a dating app. Every single one of those actions triggered a massive, invisible chain reaction inside a relational database.
It’s old. Honestly, in tech years, it’s practically a dinosaur. But it’s the kind of dinosaur that somehow survived the asteroid and now runs the local DMV. People keep trying to replace it with "cooler" NoSQL options, yet here we are, fifty years later, and the world still spins on rows and columns.
What is a relational database anyway?
Think about a massive Excel spreadsheet. Now, imagine that spreadsheet has a brain. A relational database is essentially a collection of data points with pre-defined relationships. Everything is organized into tables. These tables are made of columns (the categories) and rows (the specific entries).
The magic happens with "keys." You’ve got a Primary Key—a unique ID like your Social Security number—that identifies a specific row. Then you’ve got a Foreign Key, which is just that same ID sitting in a different table to link them together. It’s like a digital game of "connect the dots" that keeps your data from turning into a pile of digital garbage.
Back in 1970, a guy named Edgar F. Codd at IBM published a paper called "A Relational Model of Data for Large Shared Data Banks." Before Codd, databases were a nightmare. They were "hierarchical" or "network" based, which basically meant if you wanted to find a piece of data, you had to know exactly how it was physically stored on the disk. If you changed the data, the whole program broke. Codd said, "That’s stupid. Let’s separate the logic of the data from the physical storage."
He was right.
The ACID test: Why your money doesn't just vanish
Why do we still use this stuff? Because of ACID. No, not the psychedelic kind. In the world of relational database management, ACID stands for Atomicity, Consistency, Isolation, and Durability.
Imagine you are transferring $100 to your mom. Two things must happen: $100 leaves your account, and $100 enters hers. If the power goes out halfway through, you don't want that money to just... evaporate.
- Atomicity ensures the whole transaction happens, or none of it does. It’s all or nothing.
- Consistency means the database follows the rules. You can't have a negative balance if the rules say "no negative balances."
- Isolation ensures that if your brother is also sending her money at the exact same second, the transactions don't trip over each other.
- Durability means once the "Success" message pops up, that data is carved in stone. Even if the server explodes five seconds later, the record is safe.
Newer "NoSQL" databases—like MongoDB or Cassandra—often trade these strict rules for speed and scale. That’s fine for "liking" a post on Instagram. It is absolutely not fine for your mortgage payment.
📖 Related: Why Laptop Trays for Lap Use are Actually a Health Essential
The players: From Big Tech to Open Source
You’ve likely heard some of the names. Oracle is the giant in the room, mostly because they charge a fortune and have been around forever. Then you have Microsoft SQL Server, which is the backbone of many corporate offices.
But the real heroes are the open-source ones.
- PostgreSQL: Often called "Postgres," this is the darling of the dev world right now. It’s incredibly powerful, handles complex data types, and it’s free.
- MySQL: This is the engine under the hood of WordPress. It’s fast, reliable, and basically built the modern web.
- SQLite: You probably have a hundred of these on your phone right now. Every app uses a tiny, self-contained relational database called SQLite to store your settings and messages.
The SQL Language: The Only Universal Truth in Tech
If the database is the warehouse, SQL (Structured Query Language) is the forklift driver.
It’s a declarative language. That means you don’t tell the computer how to find the data; you just tell it what you want. You say, "SELECT name FROM users WHERE city = 'Chicago';" and the database engine figures out the most efficient way to grab those names.
It’s surprisingly readable. Honestly, it’s one of the few things from the 70s that hasn't needed a total rewrite. Whether you're using a multi-million dollar Oracle setup or a tiny Postgres instance on a laptop, the SQL you write will look almost identical.
Is NoSQL killing the relational model?
Short answer: No.
🔗 Read more: 101st Airborne Black Hawk Replacement: What Really Happened with the MV-75
Longer answer: There was a huge panic about ten years ago. Everyone said, "Relational databases can't scale! Big Data is too big for tables!" People flocked to NoSQL because it allowed for "unstructured" data—just throw a bunch of JSON files into a bucket and hope for the best.
It turns out, structure is actually quite helpful.
Most modern systems are now "polyglot persistence." That’s a fancy way of saying they use both. A company might use a relational database for their user accounts and financial records (where accuracy is everything) and a NoSQL database for their real-time chat logs or analytics (where speed is everything).
The biggest weakness of a relational database is "horizontal scaling." It’s hard to split one giant table across fifty different servers without things getting complicated. But with modern cloud tech like Amazon RDS or Google Cloud Spanner, even that limitation is starting to disappear.
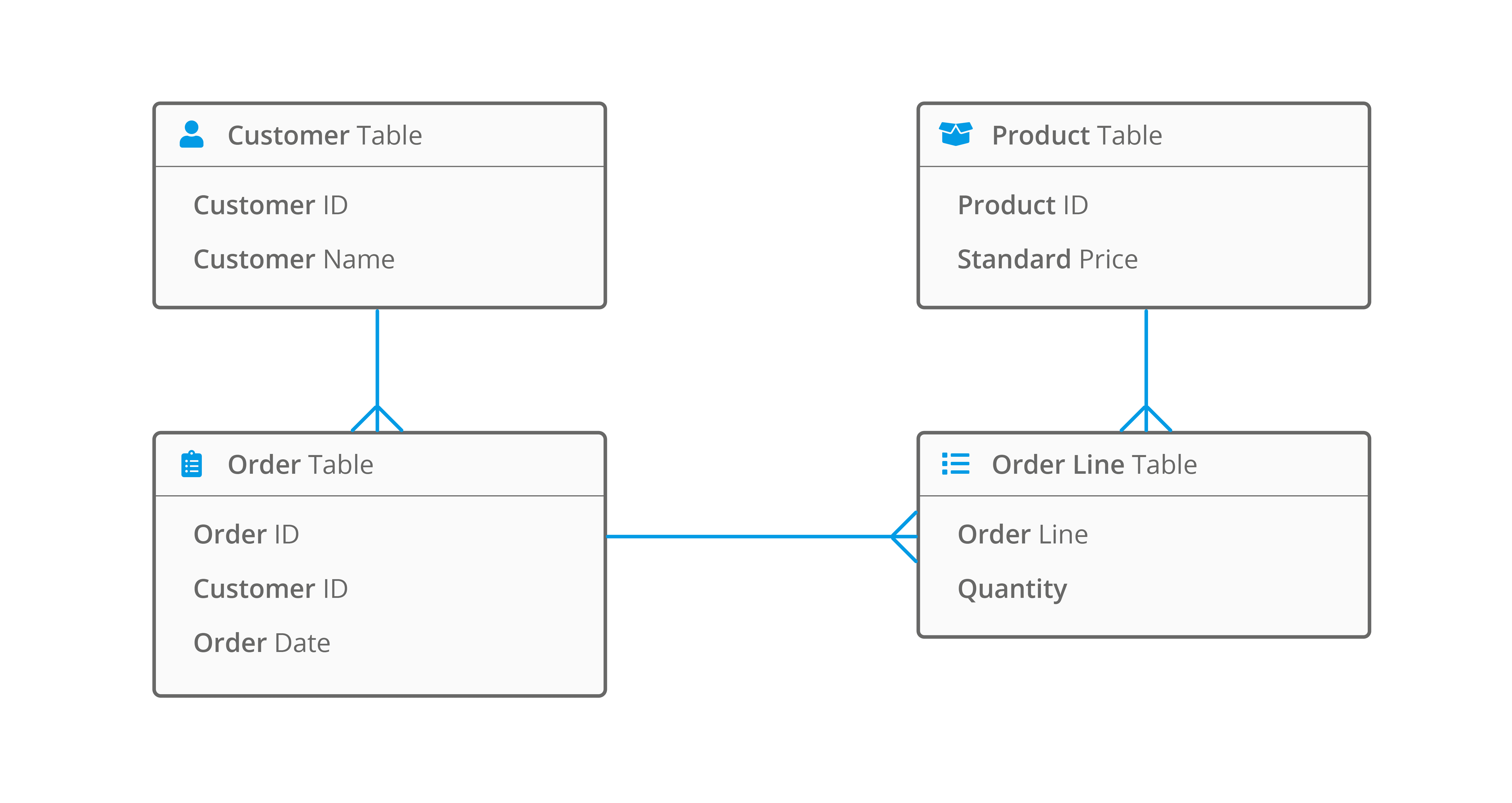
Normalization: The art of not repeating yourself
In a well-designed relational database, you never store the same piece of information twice. This is called "Normalization."
If a customer named John Smith buys ten different items, you don't write "John Smith" ten times. You write "John Smith" once in a Customers table. In the Orders table, you just put John’s ID number.
This saves space. More importantly, it prevents errors. If John Smith changes his name to John Doe, you only have to change it in one place. In a messy, non-relational system, you might change it in five places and forget the other five, leading to a "data integrity" nightmare where John is two different people at the same time.
How to actually start using this
If you're looking to move beyond spreadsheets, don't just jump into the deep end. Start small.
- Download DBeaver or TablePlus: These are "GUI" tools. They let you look at a database like a spreadsheet so you aren't just staring at a black command prompt.
- Learn the "JOIN": This is the most important concept. It’s how you pull data from two different tables at once. Once you understand a
LEFT JOINvs. anINNER JOIN, you’re officially a data person. - Pick a project: Don't just read about it. Try to build a database for something simple, like your personal book collection or a workout log. You'll quickly realize why "one big table" is a bad idea.
The relational database isn't going anywhere. It is the bedrock of the digital economy. It’s predictable, it’s rigorous, and it works. In a world of hype-driven tech cycles, there’s something deeply comforting about a technology that just does exactly what it says on the tin.
Immediate Next Steps for Your Data Journey
- Install PostgreSQL: It is the industry standard for a reason. Most cloud providers offer a free tier, or you can run it locally using an app like PostgresApp (for Mac) or the official installer for Windows.
- Map your entities: Before touching a keyboard, grab a piece of paper. Draw boxes for the "things" you want to track (Users, Products, Invoices). Draw lines between them to show how they connect. This is your "Schema."
- Practice SQL on real data: Use sites like SQLZoo or Mode Analytics. They have interactive environments where you can run queries against real-world datasets without breaking anything.
- Audit your current "Shadow DBs": Look at your company's messy Excel sheets. Ask yourself: "Which of these would be safer and faster if they were in a relational database?" Usually, it's any sheet where you're constantly copy-pasting the same names or IDs.