You're staring at a nested data structure. Maybe it’s a DOM tree in a browser, or perhaps it's a file directory on a server that hasn't been cleaned since 2019. You need to touch every single node. Most people just reach for a standard recursive function and call it a day. But if you’re dealing with preorder traversal of tree logic in a production environment, that "simple" recursion is a ticking time bomb for your stack memory.
Traversing a tree isn't just about visiting nodes; it’s about the order of operations. In a preorder approach, you're looking at the root first, then diving into the left subtree, and finally hitting the right. It sounds academic. It feels like something you only do to pass a LeetCode medium. Honestly, though? It’s the backbone of how compilers read your code and how XSLT processors transform data. If you get the order wrong, your entire data dependency chain collapses.
The Mechanics of "Root-Left-Right" and Why It Matters
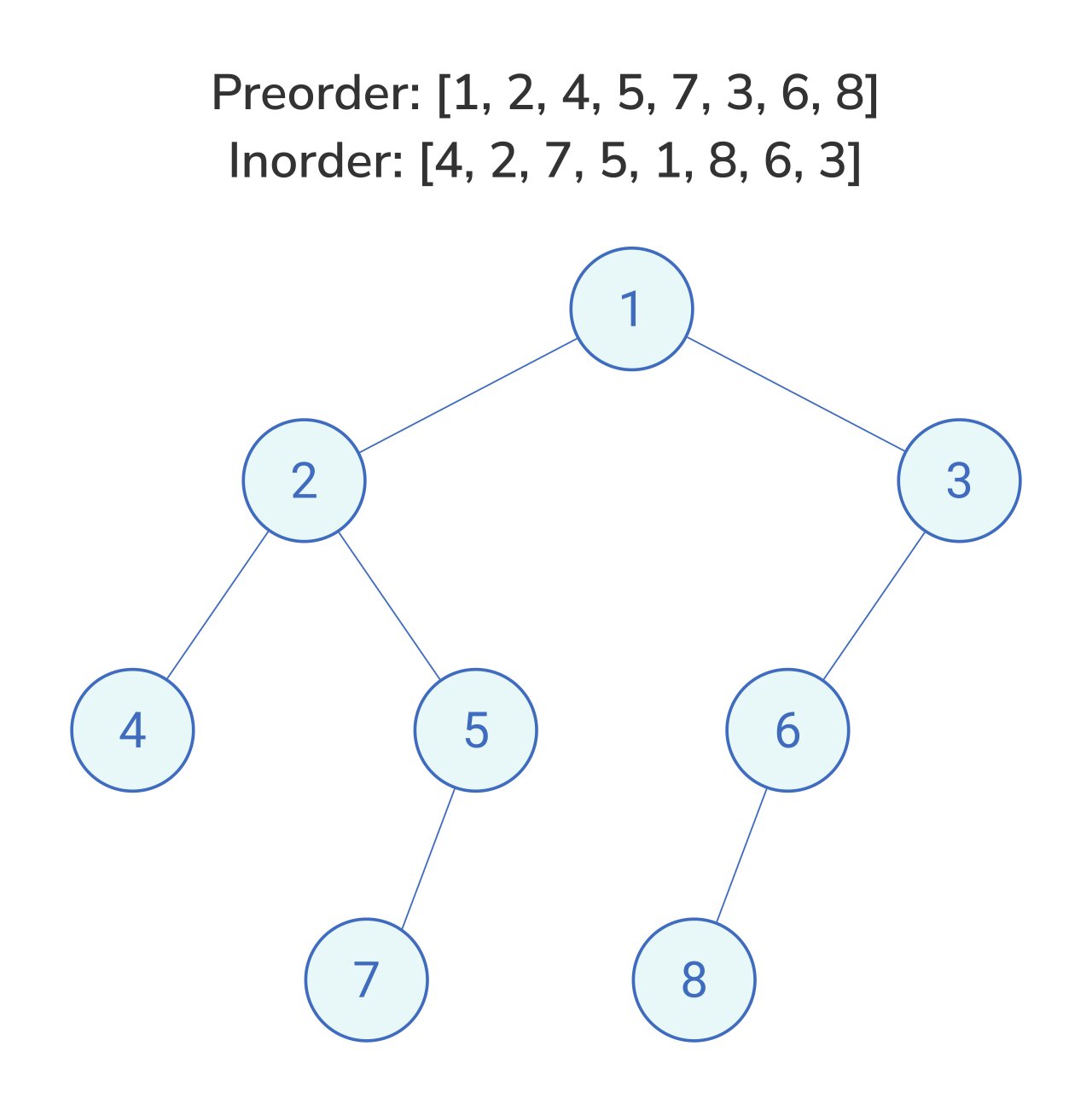
Let's get the basics out of the way. When we talk about preorder traversal of tree structures, we are describing a specific flavor of Depth-First Search (DFS). You process the parent before you ever touch the children.
Think about a document outline. You read the Chapter Title (the Root) before you read the first Section (the Left child) or the second Section (the Right child). It's intuitive for humans. We like to know the context before we see the details. In computer science, this "top-down" approach is essential for cloning a tree. You can't really build a copy of a child node if you haven't established where its parent lives in memory yet.
The algorithm is deceptively simple:
- Visit the current node (the data part).
- Recursively visit the left subtree.
- Recursively visit the right subtree.
If you visualize this, you’re tracing the "outside" of the tree starting from the top and hugging the left side. It’s the way most people naturally draw a path through a hierarchy with a pencil.
The Problem With "Classic" Recursion
Recursion is elegant. It's also dangerous. When you perform a preorder traversal of tree using a recursive function, every step down the tree adds a new frame to the call stack.
📖 Related: How to actually make Genius Bar appointment sessions happen without the headache
If your tree is "balanced"—meaning it looks like a nice, bushy triangle—you’re fine. The stack depth is $O(\log n)$. But what if your data is skewed? Imagine a tree that’s basically a long, straight line of nodes all leaning to the left. Suddenly, your $O(n)$ space complexity on the stack triggers a StackOverflowError. I’ve seen this happen in production with legacy XML files that were 50,000 levels deep. It wasn't pretty.
To avoid this, seasoned engineers often switch to an iterative approach using an explicit Stack data structure. It's uglier to look at. It’s harder to explain to a junior dev. But it’s bulletproof. You push the root onto a stack, and then while the stack isn't empty, you pop a node, process it, and push its children.
Wait—here's the trick: You have to push the right child first, then the left. Because a stack is Last-In-First-Out (LIFO), pushing the left child last ensures it gets popped and processed first, maintaining that crucial preorder sequence.
Real-World Applications You’re Using Right Now
It’s easy to dismiss this as "just theory." You shouldn't.
One of the most practical uses for preorder traversal of tree logic is in expression trees. When a compiler looks at a mathematical expression like $3 + 4$, it might represent this as a tree with $+$ at the top. A preorder traversal would yield $+ 3 4$. This is Polish Notation. While we don't write math that way in daily life, it’s much easier for a machine to evaluate because it removes all ambiguity regarding the order of operations without needing parentheses.
Another huge area? Directory structures.
👉 See also: IG Story No Account: How to View Instagram Stories Privately Without Logging In
If you’re writing a script to list every folder and file on a hard drive, you use preorder. You need to print the directory name before you list the files inside it. If you used postorder (visiting children first), you’d list all the files and then the folder name at the very end, which would be incredibly confusing for a user trying to read the output.
Comparative Look: Preorder vs. The Others
Sometimes people confuse preorder with its siblings.
- In-order: This is for binary search trees. It gives you the data in sorted order. You visit the left, then the root, then the right.
- Post-order: This is for deleting trees or calculating the size of a directory. You have to handle the children before you can handle the parent.
Preorder is unique because it's the "announcer." It tells the system what’s coming before it arrives.
Handling Complexity in Non-Binary Trees
The examples above assume binary trees (two children). But what about a "General Tree" or an "N-ary Tree"? In those cases, the preorder traversal of tree logic shifts slightly. You visit the root, and then you iterate through the children from left to right.
In the web world, the DOM (Document Object Model) is a massive N-ary tree. When a browser starts rendering a page, it doesn't wait for every single element to be parsed. It uses a streaming-style preorder logic to start showing the top-level containers and headers while the rest of the content is still loading.
If you are a JavaScript developer working with NodeIterator or TreeWalker APIs, you are literally interacting with these traversal algorithms. Using TreeWalker with a filter is often more performant than a custom recursive function because the browser’s engine (like V8 or SpiderMonkey) handles the stack management at the C++ level.
✨ Don't miss: How Big is 70 Inches? What Most People Get Wrong Before Buying
Why Memory Layout Actually Matters (The Cache Miss)
Here is something they don't teach in bootcamps: CPU cache locality.
When you perform a preorder traversal of tree, the way your nodes are laid out in physical RAM determines how fast your code runs. In languages like C or C++, if your nodes are scattered all over the heap, your CPU will constantly "miss" the cache. It has to go all the way to the slow RAM to fetch the next node's data.
High-performance systems sometimes use "Linearized Trees." They perform a preorder traversal once, then store the nodes in an array in that exact order. This way, the next time the data needs to be processed, the CPU can just stream through the array. It’s a massive speed boost. If you're working on a game engine or a high-frequency trading platform, this distinction between the "logical tree" and the "physical array" is what separates the pros from the amateurs.
Myths and Misconceptions
People think preorder is always the fastest. It isn't.
There’s a myth that preorder is inherently "better" for searching. Actually, if you’re looking for a specific value in a Binary Search Tree (BST), you don't do a full traversal at all. You use the BST property to discard half the tree at every step. A full preorder traversal of tree is $O(n)$, whereas a search is $O(\log n)$. Using the wrong one is a classic "senior dev" mistake when they’re rushing.
Actionable Steps for Implementation
If you are about to implement a preorder traversal of tree in your project, do not just copy-paste the first snippet you see on StackOverflow. Follow these steps:
- Assess Depth: If your tree depth is guaranteed to be small (under 100 levels), use recursion. It’s cleaner and easier to maintain.
- Go Iterative for Scale: If you’re dealing with user-generated data or massive hierarchies, use an explicit stack. Your server's uptime will thank you.
- Consider Threading: If the "processing" step for each node is heavy (like resizing an image or making an API call), look into parallel DFS. Note that standard preorder is inherently sequential, so you might need to reconsider your architecture if speed is the bottleneck.
- Language-Specific Tools: Use built-in iterators. In Python, use a generator with
yield. In Java, use theSpliteratorinterface if you’re on a modern version.
Don't treat tree traversal as a solved problem. Treat it as a tool that needs to be sharpened for the specific wood you're cutting. Whether you’re building a custom file explorer or just trying to organize a complex JSON response, the order in which you touch your data changes everything.
Start by auditing your current recursive functions. Check for "base case" leaks. Ensure that your null checks are at the very top of the function. Small changes in your traversal logic can lead to massive gains in reliability.