You're staring at a LeetCode screen. The problem is 2161. partition array according to given pivot. It looks easy—too easy. You think, "I'll just use quicksort logic." Then you see the word "stable." Suddenly, your quick-and-dirty swap logic is useless. Stability in algorithms means that if two numbers are the same, they have to stay in the same relative order they started in. Most partitioning logic, like the Hoare or Lomuto schemes we learned in college for Quicksort, completely trashes stability.
If you've ever felt like coding challenges are just tests of how well you can remember tiny, annoying constraints, you're not alone. But this specific problem is actually a fantastic lesson in memory management and the trade-offs between space and time complexity. It’s not just about passing the test cases; it's about understanding how we move data through memory efficiently.
What is the Actual Goal of LeetCode 2161?
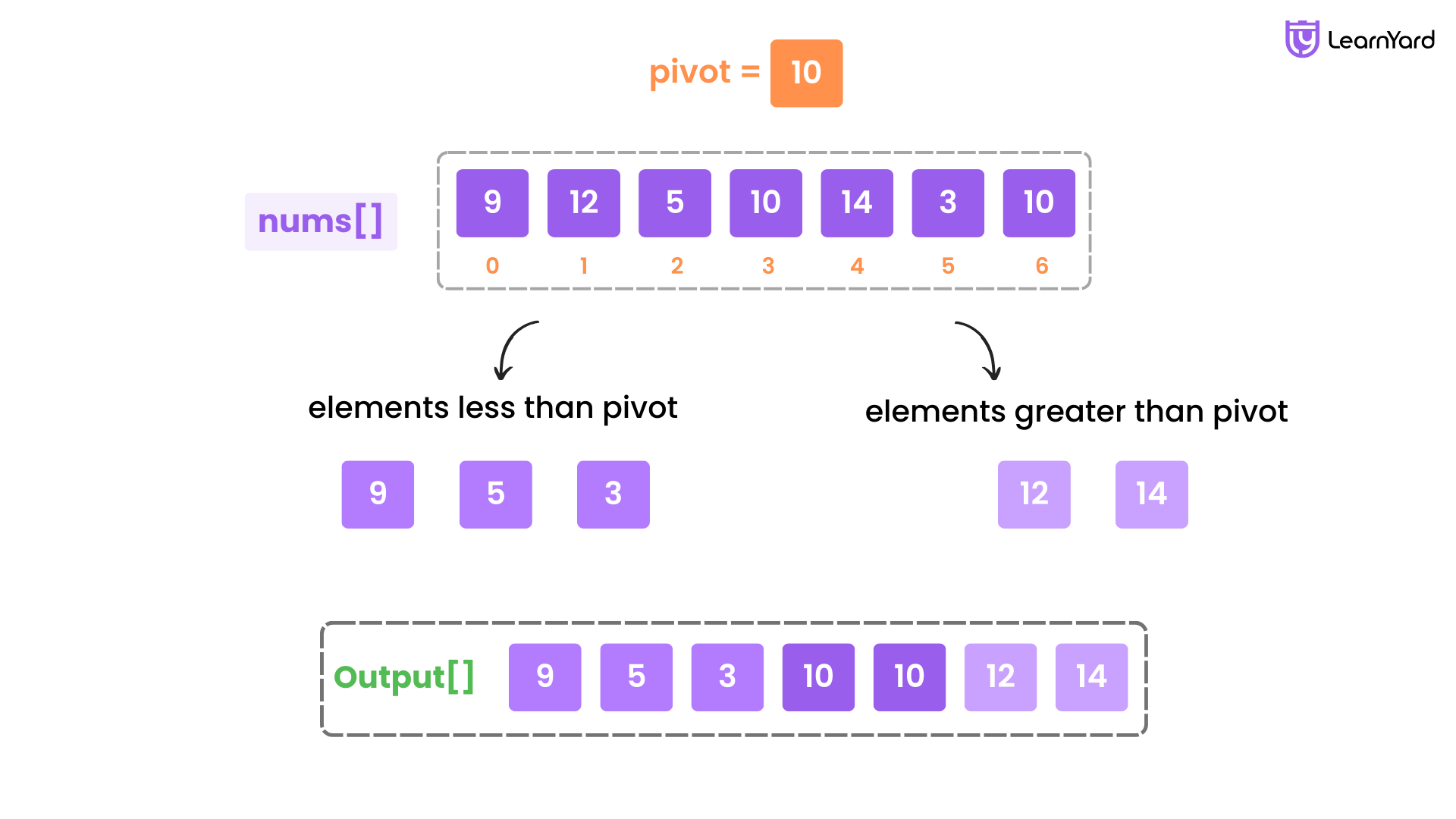
The prompt is straightforward. You get an array of integers and a specific "pivot" value. You need to rearrange the array so that everything smaller than the pivot comes first, everything equal to the pivot comes next, and everything larger comes last.
But here’s the kicker: the relative order of the elements must be preserved. If 10 appeared before 7 in the original array and both are smaller than the pivot, 10 must still appear before 7 in your final result. This requirement for stability is what stops you from using a simple two-pointer swap.
The Instinctive (and Often Wrong) Approach
Most people try to do this "in-place." They think they can be clever with pointers and avoid using extra memory. While in-place partitioning is the holy grail of sorting algorithms, doing it stably and in linear time is actually quite complex. In a technical interview or a timed competitive programming round, trying to write a stable in-place partition is usually a trap. You'll likely end up with $O(n^2)$ time complexity or a very buggy $O(n \log n)$ approach.
Honestly? Don't overthink it. The constraints on LeetCode for 2161 usually allow for $O(n)$ space. This means creating a new array is not just okay—it's the preferred strategy.
The Three-Pass Strategy (The "Safe" Way)
If you want code that is readable and guaranteed to work, you go with the three-pass approach. It’s simple. You iterate through the array three times.
First, you grab everything smaller than the pivot. Then, you grab everything equal to it. Finally, you grab everything larger.
def pivotArray(nums, pivot):
res = []
# Pass 1: Less than
for x in nums:
if x < pivot:
res.append(x)
# Pass 2: Equal to
for x in nums:
if x == pivot:
res.append(x)
# Pass 3: Greater than
for x in nums:
if x > pivot:
res.append(x)
return res
Is it the most "efficient" in terms of raw CPU cycles? Not quite, because you're looping three times. But the time complexity is still $O(n)$. In the real world, readability often beats micro-optimizations. If a teammate has to debug this six months from now, they will thank you for this clear logic.
Two Pointers, One Pass: The Performance Tweak
If you’re feeling fancy, you can do this in a single pass. Well, technically two pointers moving towards the middle, or two pointers filling a pre-allocated array.
Think about it this way. We know the size of the final array is the same as the original. We can pre-allocate an array of that size. We use one pointer starting at the beginning to place the "smaller" elements and one pointer starting at the end to place the "larger" elements.
Wait.
There's a problem with that. If we fill the "larger" elements from the end of the new array starting from the end of the original array, we have to be careful about the order.
To keep it stable for the "greater than" elements while moving in one pass, you actually have to iterate from both ends of the original array simultaneously. You track an i pointer for the front and a j pointer for the back. It's a bit of a mental gymnastic routine.
Memory Complexity: The Elephant in the Room
When we talk about 2161. partition array according to given pivot, we have to talk about space. Because we are returning a new array, the space complexity is $O(n)$.
Some purists argue that since the problem requires us to return an array, that space shouldn't count toward the complexity. In academic terms, that’s "extra space." But let’s be real: your RAM doesn't care about academic definitions. If you have a billion integers, you need another several gigabytes to hold that result.
If you were working on an embedded system with 16KB of RAM, you couldn't use this approach. You would be forced to use an in-place algorithm like the Stable Partition algorithm (often found in the C++ Standard Template Library as std::stable_partition). That algorithm usually works in $O(n \log n)$ time if extra memory isn't available, or $O(n)$ if it can grab a temporary buffer.
👉 See also: What is the Newest Kindle Fire? The 2026 Tablet Lineup Explained
Why Does Stability Matter?
You might wonder why LeetCode 2161 insists on stability. In a vacuum (like a list of random integers), it doesn't. Who cares if the 5 at index 2 stays before the 5 at index 5?
But imagine the array isn't just integers. Imagine it's a list of objects, like "Orders" in an e-commerce system. Each order has a priority (the pivot) and a timestamp. If you partition the orders by priority but lose the relative order of the timestamps, you've just broken your "first-come, first-served" logic within each priority level.
That’s why stability is a "must-have" in many real-world database and UI sorting operations.
Common Pitfalls to Avoid
- Off-by-one errors: If you're using the two-pointer approach, it's incredibly easy to overwrite the middle section where the pivot values are supposed to go.
- Forgetting the Pivot: Some people focus so much on the "less than" and "greater than" that they forget to count how many times the pivot itself appears.
- Language-specific overhead: In Python,
res.append()is generally fast, but if you're doing it millions of times, pre-allocatingres = [0] * len(nums)and using indices is faster. In Java or C++, you absolutely should pre-allocate the array to avoid the overhead of dynamic resizing.
Real-World Implementation Insights
If you're writing this for a production system, you’d likely use built-in functions. For example, in Python, you might just do:
return [x for x in nums if x < pivot] + [x for x in nums if x == pivot] + [x for x in nums if x > pivot]
✨ Don't miss: The iPod Shuffle with a Screen: Why Apple Never Actually Made One
It’s elegant. It’s "Pythonic." It’s also essentially the three-pass strategy wrapped in syntactic sugar.
Is it the fastest? Usually not. List comprehensions are fast, but creating three separate intermediate lists before joining them uses more memory than necessary. If you're dealing with massive datasets, you'd want a more memory-efficient stream-based approach.
Taking Action: How to Master This Problem
To truly understand 2161. partition array according to given pivot, don't just solve it and move on. Try these variations:
- Solve it with three pointers: One for the current element, one for the next "low" slot, and one for the next "high" slot.
- Constraint challenge: Try to solve it with only $O(1)$ extra space (not counting the output array) while maintaining $O(n)$ time. (Spoiler: This is very difficult to do while keeping it stable).
- Language swap: If you did it in Python, try it in C++. Notice how managing the memory yourself changes your perspective on the problem.
The next step is to look at your current solution and analyze the cache locality. Arrays are contiguous in memory. When you do a single pass, you're being "cache-friendly." When you do three passes, you're jumping back to the start of the array repeatedly. On modern CPUs, this can actually make a measurable difference in performance for very large arrays.
Start by implementing the simple three-pass version to ensure you understand the stability requirement. Once that passes, try to refactor it into a single-pass solution using a pre-allocated result array and two pointers. This progression from "make it work" to "make it fast" is exactly how senior engineers approach system design.
Next Steps for You:
Open your IDE and implement the two-pointer approach where you fill the result array from both ends in one go. Pay close attention to how you handle the "equal to pivot" elements—they are the trickiest part of the one-pass logic. Once you've nailed that, you'll have a much deeper grasp of array manipulation than someone who just copied a basic solution.