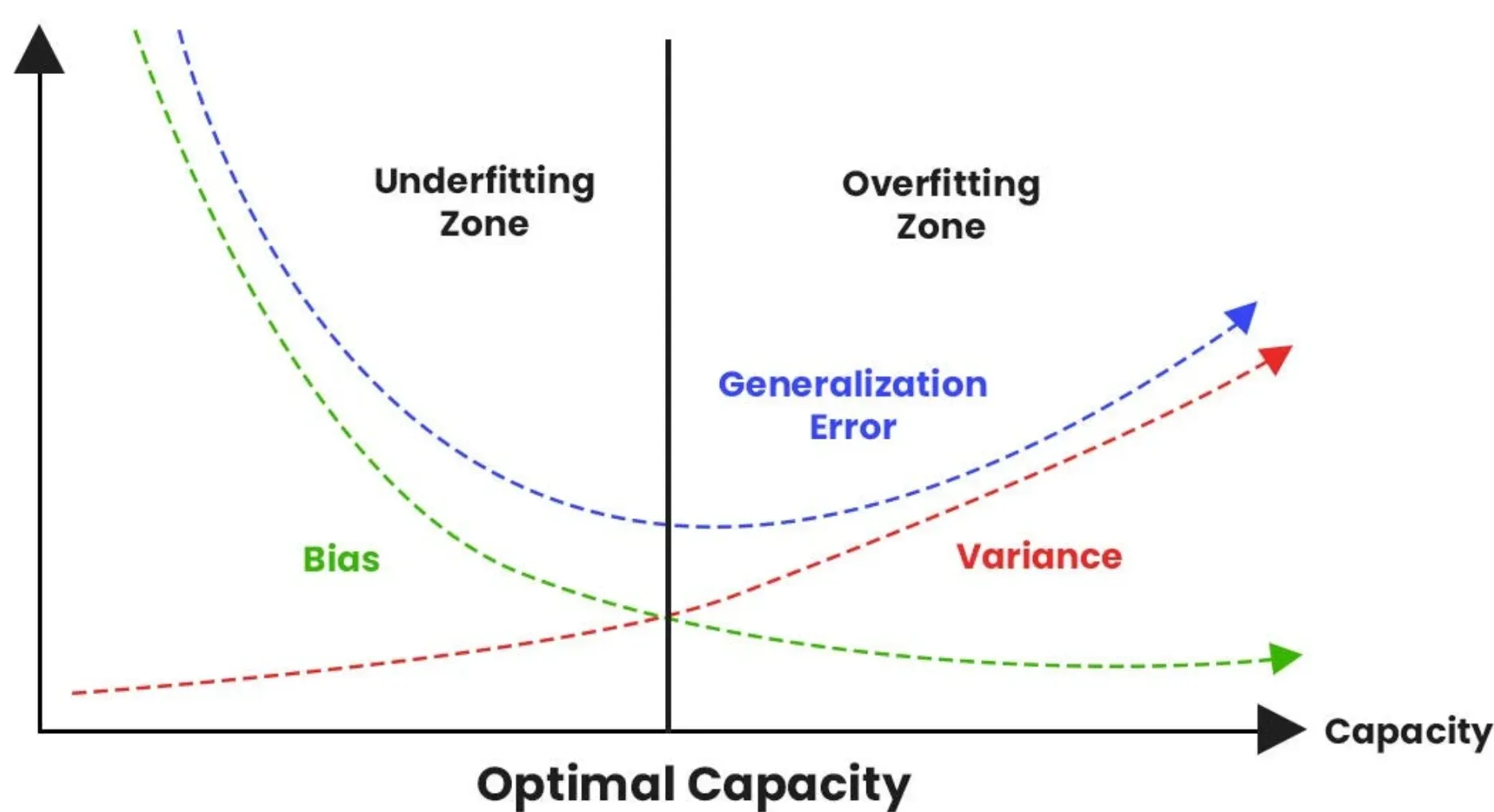
You've built a model. It looks perfect on your training data, hitting 99% accuracy like a champ. But then you throw it at real-world data and it falls apart. Total disaster. This is the classic "overfitting" trap where your machine learning model basically memorizes the noise instead of learning the actual signal. To fix this, we use regularization. Specifically, L1 regularization L2 regularization techniques.
Regularization is just a fancy word for "keep it simple." If your model is too complex, it gets distracted by outliers. By adding a penalty to the loss function, we force the model to behave. It’s like a coach telling an athlete to focus on the basics rather than showing off.
The Math Behind the Madness
Usually, we want to minimize a loss function like Mean Squared Error (MSE). But with regularization, we add a little extra weight to that equation. We call this a penalty term.
In L1 regularization (Lasso), we add the absolute value of the weights:
$$\text{Loss} = \text{MSE} + \lambda \sum_{j=1}^{p} |w_j|$$
For L2 regularization (Ridge), we add the squared value of those weights:
$$\text{Loss} = \text{MSE} + \lambda \sum_{j=1}^{p} w_j^2$$
That $\lambda$ (lambda) is your tuning knob. Set it to zero? No regularization. Set it too high? Your model becomes too "lazy" to learn anything. It’s a delicate balance.
L1 Regularization: The Minimalist
L1 is often called Lasso (Least Absolute Shrinkage and Selection Operator). It’s the Marie Kondo of machine learning. It looks at your features and asks, "Does this spark joy?" If a feature isn't contributing much, L1 will literally drive its weight to zero. It deletes it.
This makes L1 incredible for feature selection. Imagine you have a dataset with 500 columns, but only 10 actually matter. L1 will find those 10 and ignore the rest. It produces sparse models. Sparse is just a cool way of saying "mostly zeros."
Why does it do this? Geometrically, the L1 penalty creates a diamond-shaped constraint. When the optimization hits a corner, weights drop to zero. It's abrupt. It's efficient. Honestly, if you're dealing with massive datasets where you suspect most variables are junk, L1 is your best friend.
L2 Regularization: The Pacifist
L2, or Ridge Regression, is less aggressive. It doesn't like to delete things. Instead, it shrinks every weight proportionally. It says, "Okay, everyone can stay, but you all have to be smaller."
The squared penalty means that large weights get punished way harder than small ones. This prevents any single feature from dominating the prediction. It keeps things democratic. If you have highly correlated features—like height and weight—L2 will distribute the "importance" between them rather than picking one and killing the other.
Most of the time, L2 performs better than L1 in terms of raw accuracy. It's the "safe" choice. It handles multicollinearity like a pro. Robert Tibshirani, who actually proposed Lasso in 1996, noted that while L1 helps with interpretation, L2 is often the workhorse for stable predictions.
When Should You Use Which?
Choosing between L1 and L2 isn't always obvious. It depends on your data's personality.
- Go with L1 if: You have a ton of features and you think many of them are useless. You want a model that's easy to explain to your boss. You need to save memory.
- Go with L2 if: You care about every little bit of information. You have features that are closely related. You want a stable model that doesn't change wildly when you add a few new data points.
Sometimes, you don't want to choose. That's where Elastic Net comes in. It's basically a hybrid of both. It adds both the $|w|$ and the $w^2$ penalties. If you're feeling indecisive or your data is incredibly messy, Elastic Net is a solid middle ground.
Real World Messiness: A Concrete Example
Think about predicting house prices. You have data on square footage, number of rooms, the color of the mailbox, and the name of the previous owner's dog.
📖 Related: Getting Around the Apple Store Short Hills Mall Without the Usual Headache
An L1 model would likely keep square footage and rooms, while setting the "dog's name" and "mailbox color" weights to exactly zero. It cleans the house.
An L2 model would keep everything. It would give square footage a high weight, and the dog's name a tiny, almost invisible weight, but it would still be there.
In a high-stakes environment like medical diagnosis, this matters. If a model uses 1,000 genetic markers, L1 might find the 5 "driver" genes. That’s a medical breakthrough. L2 would use all 1,000, which might be slightly more accurate but tells the doctor nothing about the underlying cause.
Implementation in Python
Most people use Scikit-Learn for this. It’s basically the industry standard.
from sklearn.linear_model import Lasso, Ridge
# Lasso is L1
lasso_model = Lasso(alpha=0.1)
lasso_model.fit(X_train, y_train)
# Ridge is L2
ridge_model = Ridge(alpha=1.0)
ridge_model.fit(X_train, y_train)
Note that Scikit-Learn uses alpha instead of lambda. Don't let that trip you up. It's the same thing. One big catch: you must scale your data before using l1 regularization l2 regularization. If one feature is measured in millions and another in decimals, the penalty will hit them unfairly. Standardize your features first. Always.
✨ Don't miss: The Real Definition for Resistance: Why Your Electronics (and Your Physics Teacher) Care So Much
Misconceptions That Kill Models
A big mistake people make is thinking regularization is a silver bullet for bad data. It's not. If your data is biased or your features have no relationship to the target, adding a penalty won't save you. It just makes the model suck in a more "regularized" way.
Another weird myth is that L1 is always faster. While the final model might be faster (because it has fewer variables), the training process for Lasso can actually be slower because the absolute value function isn't differentiable at zero. It requires more complex optimization algorithms like coordinate descent.
Moving Forward With Your Model
Don't just guess which one to use. Use Cross-Validation.
Run a grid search over different values of $\alpha$ and different types of regularization. Let the data tell you what it likes. Use GridSearchCV or RandomizedSearchCV in Python to test a range of L1 and L2 penalties.
Check your coefficients. If you see a lot of zeros with L1, you know those features are garbage. If you see weights that are still huge even with L2, you might need a stronger penalty.
Start with L2 for stability. If the model is too bloated, pivot to L1 or Elastic Net. Scaling your data with StandardScaler should be your very first step before even touching the regularization parameters. This ensures the penalty is applied equally across all your inputs. Finally, always keep a separate test set that your model has never seen to verify that your regularization actually worked and isn't just a mathematical fluke.