If you’ve spent any time on the internet lately, you’ve seen the term LLM thrown around like confetti. People talk about them as if they’re sentient beings, or maybe just really fancy calculators. But when you’re staring at that blinking cursor on your screen, you’re probably wondering: is ChatGPT an LLM, or is it something else entirely?
Honestly? It's both.
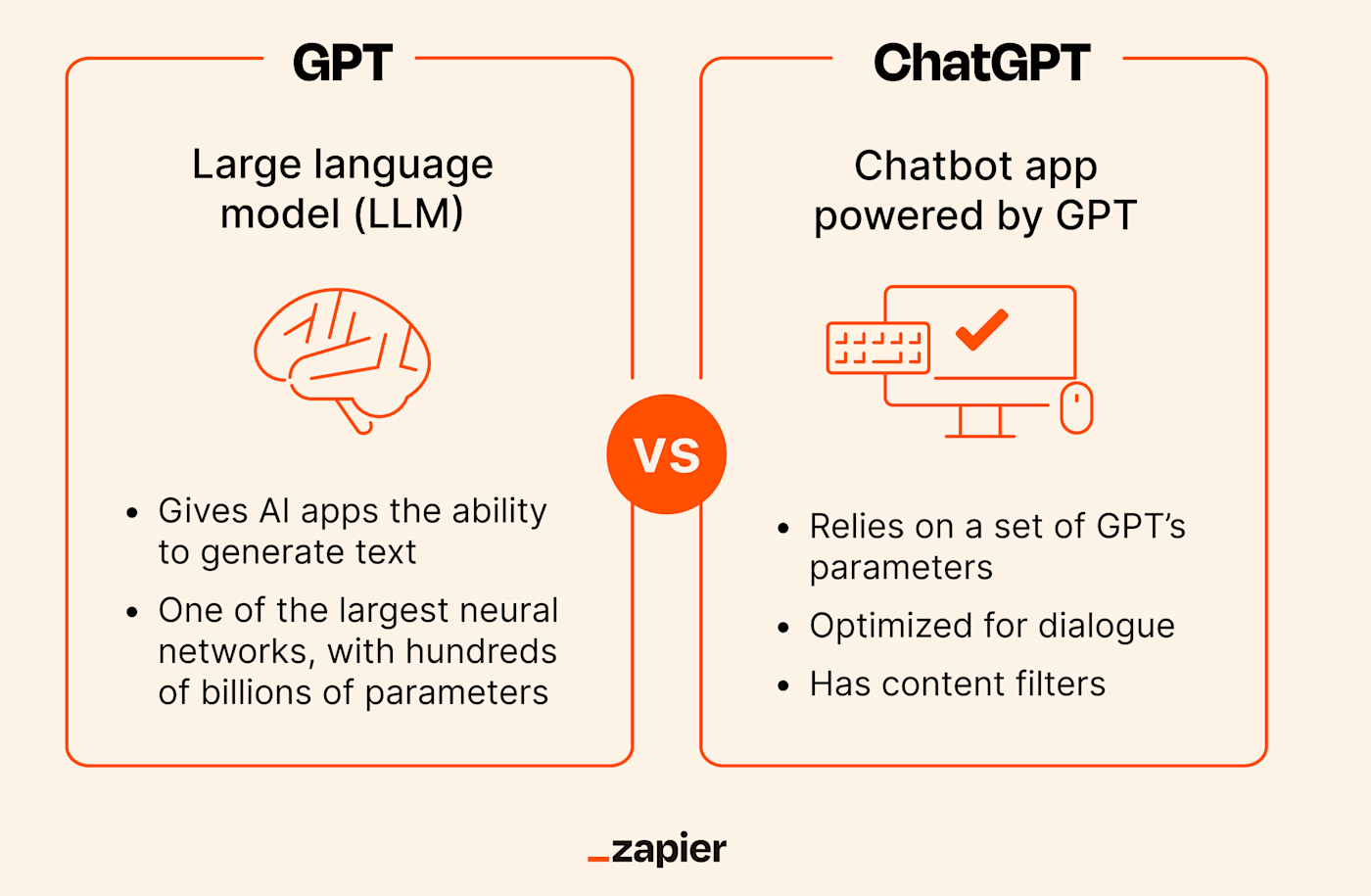
It is a Large Language Model at its core, but calling it just an LLM is like calling a Ferrari just an "engine." While the engine is what makes the car go, there’s a whole lot of chassis, leather seating, and aerodynamics involved that turn that engine into a drivable vehicle. ChatGPT is the "car" built around the engine of a model like GPT-4o or GPT-4.
The basic tech behind the curtain
To understand if is ChatGPT an LLM, we have to look at what that acronym actually stands for. Large Language Models are essentially massive statistical prediction machines. They don't "know" things in the way humans do. Instead, they’ve been fed almost the entire public internet—books, Wikipedia, Reddit threads, coding forums—and they've learned the patterns of human language.
When you type a prompt, the model isn't looking up an answer in a database. It’s calculating. It’s asking itself, "Based on the 500 billion sentences I’ve seen, what is the most statistically likely word to follow this one?"
It’s math. Just really, really fast math.
The "Large" part of LLM refers to the number of parameters. These are the internal variables the model uses to make decisions. While OpenAI is famously secretive about the exact specs of their newest models, industry experts like Andrej Karpathy (a founding member of OpenAI) have often described these systems as "lossy compressors" of the internet. They take a massive amount of data and squeeze it down into a set of weights that can recreate that information on demand.
The difference between the model and the product
Here is where people get tripped up.
ChatGPT is the interface. It’s the website (https://www.google.com/search?q=chatgpt.com) and the app you have on your phone. The LLM is the model running in the background. Think of it this way:
- GPT-4 / GPT-4o / GPT-3.5: These are the LLMs.
- ChatGPT: This is the product that uses those LLMs.
When OpenAI released the first version of ChatGPT in November 2022, they were using a fine-tuned version of GPT-3.5. It was a revelation because, for the first time, a raw LLM was actually easy to talk to. Before that, using an LLM required some technical knowledge or "prompt engineering" to get it to stay on track. ChatGPT added a layer of "chat-style" memory and safety filters that made it feel like a person.
Why we can't just call it a "chatbot" anymore
Back in the early 2000s, we had SmarterChild on AIM. That was a chatbot. It worked on "if-then" logic. If you said "Hello," it said "Hi!" If you asked for the weather, it pulled from a specific weather API.
ChatGPT is fundamentally different because it’s generative.
Because is ChatGPT an LLM, it can create entirely new sequences of text it has never seen before. It can write a poem about a toaster in the style of Edgar Allan Poe. It can debug a Python script. It can help you draft a breakup text that sounds "firm but gentle." A traditional chatbot couldn't do that because it didn't understand the underlying structure of language.
But there’s a catch.
Since it’s a statistical model, it can "hallucinate." This is a fancy way of saying it can confidently lie to your face. Because it's trying to predict the next word, it might decide that the most "likely" word is a factually incorrect one that happens to sound grammatically perfect. This is why experts like Professor Emily Bender have referred to these models as "Stochastic Parrots." They repeat back patterns without any actual "grounding" in reality.
The training process: How an LLM becomes ChatGPT
An LLM doesn't just wake up knowing how to be helpful. It goes through a very specific, multi-stage training process.
- Pre-training: This is the "Large" part. The model reads everything. It learns grammar, facts, and how to argue. At this stage, it’s not a "chat" bot. If you asked it a question, it might just give you more questions because it thinks it’s reading an exam paper.
- SFT (Supervised Fine-Tuning): Human trainers act out both sides of a conversation. They show the model, "Hey, when a user asks a question, this is what a good, helpful answer looks like."
- RLHF (Reinforcement Learning from Human Feedback): This is the secret sauce. Humans rank different responses from the model. They tell it, "This answer is better than that one because it’s less racist and more concise." This is what turns a raw LLM into the polished ChatGPT experience.
This third step is crucial. Without RLHF, an LLM can be unpredictable or even toxic. OpenAI, Google, and Anthropic spend millions of dollars on human labeling to ensure the model stays within certain "guardrails."
Is ChatGPT the only LLM out there?
Not even close. The world of Large Language Models is getting crowded. While ChatGPT is the household name, several other heavy hitters are competing for the crown.
Google has Gemini (formerly Bard). Gemini is unique because it was built to be "multimodal" from the ground up, meaning it handles video, audio, and text simultaneously rather than bolting them together. Then there’s Claude, built by Anthropic. Claude is often praised for having a more "human" and less "robotic" writing style than ChatGPT.
In the open-source world, Meta’s Llama models are changing everything. Because Meta released the "weights" (the actual brain of the model) for free, developers can run their own versions of an LLM on their own hardware. This is a huge deal for privacy. If you use ChatGPT, your data is going to OpenAI’s servers. If you use an open-source LLM, it stays on your machine.
What most people get wrong about ChatGPT
One of the biggest misconceptions is that ChatGPT "thinks."
It doesn't.
There is no "I" in there. When ChatGPT says, "I think that's a great idea," it is merely predicting that those words are the most appropriate response to your input. It has no consciousness, no feelings, and no personal opinions. It is a reflection of the data it was trained on.
Another mistake is treating it like a search engine. Google indexes the web and points you to sources. ChatGPT has digested the web and gives you a summary. If you need a specific, verifiable fact—like the current price of a stock or a specific court case—you’re better off using a tool that has "search" integrated (like ChatGPT's "Search" feature or Perplexity AI), which combines an LLM with live web browsing.
🔗 Read more: Why Pictures From The Fappening Still Haunt the Internet 12 Years Later
The future of the LLM landscape
We are moving past the era where we just ask is ChatGPT an LLM. The new question is: what can this LLM do?
The industry is shifting toward "Agents." Instead of just talking, these models are starting to take actions. Imagine a version of ChatGPT that doesn't just give you a recipe but actually logs into your grocery app, adds the ingredients to your cart, and schedules a delivery. That requires the LLM to interact with other software.
We’re also seeing a push toward "small" language models (SLMs). Let's face it: running a massive model like GPT-4o takes a ridiculous amount of electricity and computing power. Microsoft’s Phi-3 or Google’s Gemini Nano are designed to run on your phone or laptop. They aren't as "smart" as the giants, but they’re fast and private.
How to actually use an LLM effectively
If you want to get the most out of ChatGPT, you have to stop treating it like a human and start treating it like a very talented, slightly distracted intern.
- Be specific: Don't say "Write a blog post." Say "Write a 500-word blog post about sourdough starters for a beginner audience, using a humorous tone."
- Give it a persona: Tell it, "You are a senior software engineer with 20 years of experience." It changes the statistical probability of the words it chooses.
- Chain of Thought: If you have a complex problem, ask it to "think step-by-step." This forces the model to layout its reasoning, which drastically reduces errors.
- Verify everything: Never copy-paste a fact-heavy document without checking it. The model is a language expert, not a truth expert.
Actionable Next Steps
To truly understand the power and limitations of LLMs, you need to see how they differ in practice.
Start by taking a single, complex prompt—something like, "Explain the concept of quantum entanglement using only metaphors related to 1980s pop culture"—and run it through ChatGPT, Claude, and Gemini.
You’ll notice immediately that while they are all LLMs, their "personalities" and the way they structure information are wildly different. This exercise helps you see past the "magic" and recognize the technology for what it is: a sophisticated tool that you can master.
📖 Related: Connect Bluetooth Headphones to MacBook: Why It Fails and How to Fix It
Once you’ve done that, look into "System Instructions" in ChatGPT’s settings. This allows you to set permanent rules for how the LLM interacts with you, effectively customizing the model's behavior to fit your specific needs without having to repeat yourself in every new chat. Masters of these tools don't just use them; they calibrate them.