Ever get lost in a Wikipedia rabbit hole? You start on a page about "Capybaras," click a link to "South America," then "Amazon River," and before you know it, you're reading about the history of synthetic rubber. That’s a depth-first approach. But imagine if, instead of clicking one link and following it to the end of the earth, you opened every single link on the Capybara page in a new tab first. You’d be looking at "Rodents," "Mammals," and "Herbivores" all at once before moving any deeper.
That, in a nutshell, is breadth first search.
It’s the logic of the "level-by-level" explorer. While it might sound like a chaotic way to browse the web, it is actually the backbone of how modern networks function. Whether it's LinkedIn suggesting a "3rd-degree connection" or Google Maps finding the quickest way out of a traffic jam, BFS is usually the silent engine under the hood. It’s methodical. It’s reliable. Honestly, it’s probably the most "fair" algorithm we have because it doesn't play favorites with paths—it checks everything equally before moving on.
What Breadth First Search Is Actually Doing
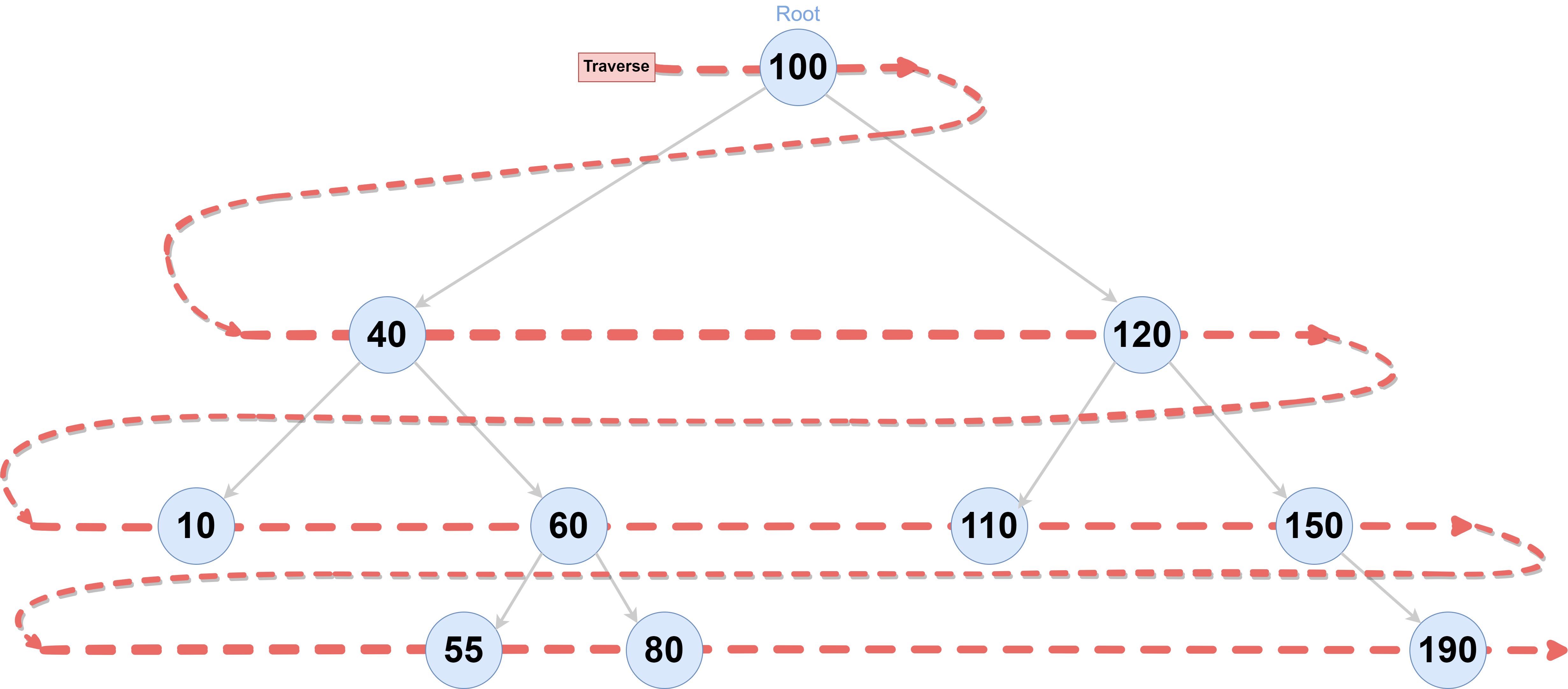
If you ask a computer scientist, they’ll tell you BFS is an algorithm for traversing or searching tree or graph data structures. But let’s keep it real. It’s basically a ripple in a pond. When you throw a stone into still water, the first wave hits the closest points. Then the next wave hits the points slightly further out. BFS does the same thing with data. It starts at a "root" node—or any random node you pick in a graph—and visits all the neighbors first. Only after it has exhausted those immediate neighbors does it move to the neighbors of the neighbors.
It uses a "Queue." Think of a line at a Starbucks. The first person to get in line is the first person to get their latte and leave. In BFS, the first node we find is the first one we explore. We "enqueue" the starting point, then we pull it out, look at its friends, put them in the line, and repeat. This First-In-First-Out (FIFO) behavior is why BFS finds the shortest path in an unweighted graph. It’s impossible for it to find a path that's five steps away before it finds one that's two steps away. It just doesn't work that way.
The algorithm is often attributed to Edward F. Moore, who was looking for a way to find the shortest path through a maze back in the late 1950s. Separately, C.Y. Lee arrived at the same logic for routing wires on circuit boards. It’s funny how two people solved the same problem because they both just wanted to get from point A to point B without wasting time.
The Anatomy of the Search
To make this work, the algorithm needs to keep track of where it’s been. Computers are surprisingly forgetful. If you don't tell the algorithm to mark a node as "visited," it will just keep bouncing back and forth between two nodes forever, like a digital ping-pong match.
🔗 Read more: The Order of the Planets From the Sun: What Everyone Gets Wrong About Our Solar System
Typically, you have three things happening:
- A way to track visited nodes (so we don't loop).
- A queue to manage the order of exploration.
- The graph itself, which is just a bunch of dots (nodes) and lines (edges).
The time complexity is $O(V + E)$. In plain English? The time it takes is proportional to the number of Vertices (the dots) plus the Edges (the connections). It’s efficient, but it’s a memory hog. Because you have to store all the nodes at the current "level" in the queue, BFS can eat up RAM faster than a Chrome browser with fifty tabs open.
Why BFS Beats Depth First Search (Sometimes)
People always ask which one is better. It's a bit like asking if a hammer is better than a screwdriver. It depends on what you're trying to fix.
Depth First Search (DFS) is like a brave explorer who goes down one dark tunnel until they hit a wall or find the treasure. It’s great if the treasure is buried deep. But if the treasure is actually just three feet away in a different tunnel, DFS might take three years to find it. BFS would find it in three minutes.
Use BFS when:
- You need the shortest path. Since BFS explores level-by-level, the first time it hits the target, it is guaranteed to have used the fewest number of edges possible.
- The graph is relatively shallow.
- You’re looking for things close to the start.
DFS is better when:
- Memory is tight.
- The graph is extremely wide (BFS would need a massive queue).
- You need to visit every node anyway, like in a game's decision tree where you're looking for any win, not necessarily the fastest one.
Real-World Chaos Where BFS Saves the Day
Let’s talk about your social life. Have you ever noticed how Facebook or LinkedIn knows you might know "John Smith"? They aren't psychics. They use BFS to calculate the distance between you and everyone else. If John is a friend of a friend, he’s at distance two. If he’s a friend of a friend of a friend, he’s at distance three. BFS maps these social layers perfectly.
Then there’s GPS. When you’re trying to get to the new taco spot across town, the map is essentially a massive graph where intersections are nodes and roads are edges. While modern GPS uses more "intelligent" versions like A* (which is basically BFS with a brain), the core logic of expanding outward to find the shortest route is pure BFS.
Even in something as simple as "Fill" tool in Photoshop—the little paint bucket icon—the computer uses a variation of BFS. It starts at the pixel you clicked and spreads outward, checking every neighboring pixel to see if it’s the same color. If it is, it changes the color and moves to that pixel's neighbors. It’s a literal digital ripple.
Peer-to-Peer Networks
If you’ve ever used BitTorrent or old-school file-sharing apps, BFS was likely involved in "neighbor discovery." Your computer asks its immediate neighbors, "Hey, do you have this file?" If they don't, they ask their neighbors. It spreads out in a radius. It’s an incredibly robust way to find information in a decentralized system where nobody is really in charge.
The Technical Nitty-Gritty (The Code Logic)
If you were to write this out, you’d probably use a simple while loop. As long as the queue isn't empty, you keep going. You pull a node out, check its neighbors, and if they haven't been visited, you mark them and shove them into the back of the line.
# A tiny peek at the logic
while queue:
current = queue.pop(0)
for neighbor in graph[current]:
if neighbor not in visited:
visited.add(neighbor)
queue.append(neighbor)
It looks simple because it is. The beauty of breadth first search is that it doesn't try to be clever. It’s just thorough.
However, we have to talk about the "Space Complexity." This is the catch. If you’re searching a graph where every node has 10 connections, by the time you’re only 4 levels deep, you’re looking at 10,000 nodes. By level 10, you're looking at 10 billion. This "branching factor" is why BFS can sometimes crash a system if the graph is too dense. It’s the "Big O" nightmare: $O(B^D)$, where B is the branching factor and D is the depth.
Surprising Weaknesses and Limitations
BFS isn't perfect. If your graph has "weights"—meaning some roads are faster than others or some paths cost more—BFS fails. It treats every connection as equal. If you have a 1-mile road that takes an hour (traffic) and a 10-mile road that takes 10 minutes (highway), BFS will pick the 1-mile road every single time because it only sees "one edge" versus "ten edges."
This is why we eventually moved to Dijkstra’s Algorithm for things like Google Maps. Dijkstra is basically BFS’s smarter cousin who considers the "cost" of the path, not just the number of steps.
✨ Don't miss: Turn on voice search: Why your phone still isn't listening properly
Also, BFS is terrible for puzzles with an infinite state space. Imagine a game of chess. The number of possible moves is so astronomical that a BFS would run out of memory before the game even really started. In those cases, we use things like Iterative Deepening, which is a weird hybrid that tries to get the best of both worlds.
How to Actually Use This Knowledge
If you’re a developer or just someone trying to understand how logic works, there are a few practical takeaways here.
- Audit your data structure first. If you’re building a feature and you need to find the "closest" anything—users, stores, servers—BFS is your go-to.
- Watch your memory. If you know your graph is incredibly wide, maybe reconsider. You don't want your app crashing because the queue grew to 4GB.
- Unweighted is the key. If all steps are equal, BFS is the fastest way to find the shortest path. Period.
Honestly, BFS is more than just a coding interview question. It’s a way of looking at the world. It teaches us that sometimes, the best way to find a solution isn't to run as fast as you can in one direction, but to carefully check your surroundings first.
Implementation Checklist
- Choose your starting node carefully.
- Initialize an empty queue and a set for visited nodes.
- Don't forget to handle "disconnected" graphs (nodes that have no path to the start).
- If your graph is "weighted," stop. Go look up Dijkstra or A* instead.
- Test with a small graph on paper first. It's easy to lose track of the queue order in your head.
The next time you’re looking for a friend in a crowded mall, you’ll probably use a version of BFS. You’ll check the immediate stores around you, then the ones a bit further out, rather than walking in a straight line for three miles and hoping for the best. It’s just natural logic, codified.
Next Steps for Mastering Graphs
- Build a simple crawler. Write a script that takes a URL and finds all links on that page, then visits them in BFS order. It’s the best way to "see" the algorithm work.
- Visualize the queue. Use a tool like VisuAlgo to watch the nodes turn colors as the BFS spreads. It makes the $O(V+E)$ concept much more intuitive.
- Compare with DFS. Implement the same search using a Stack instead of a Queue. You'll see immediately how the search pattern changes from a "circle" to a "long thin line."