Databases are messy. If you’ve ever spent three hours wondering why a simple report is missing half its data, you’ve probably met the "billion-dollar mistake." That’s what Tony Hoare, the inventor of the null reference, called it. In the world of structured query language, handling absences is just as important as handling the data itself. Using and not null sql logic isn't just a best practice; it is often the only thing standing between you and a massive production bug.
Null is not zero. It isn't an empty string or a space. It is the literal embodiment of "we don't know." When you combine this "unknown" with standard logic, things get weird.
The Logic of Nothing
Most people think in binary. True or false. Yes or no. SQL doesn't work that way. It uses Three-Valued Logic (3VL). This means every comparison can result in True, False, or Unknown.
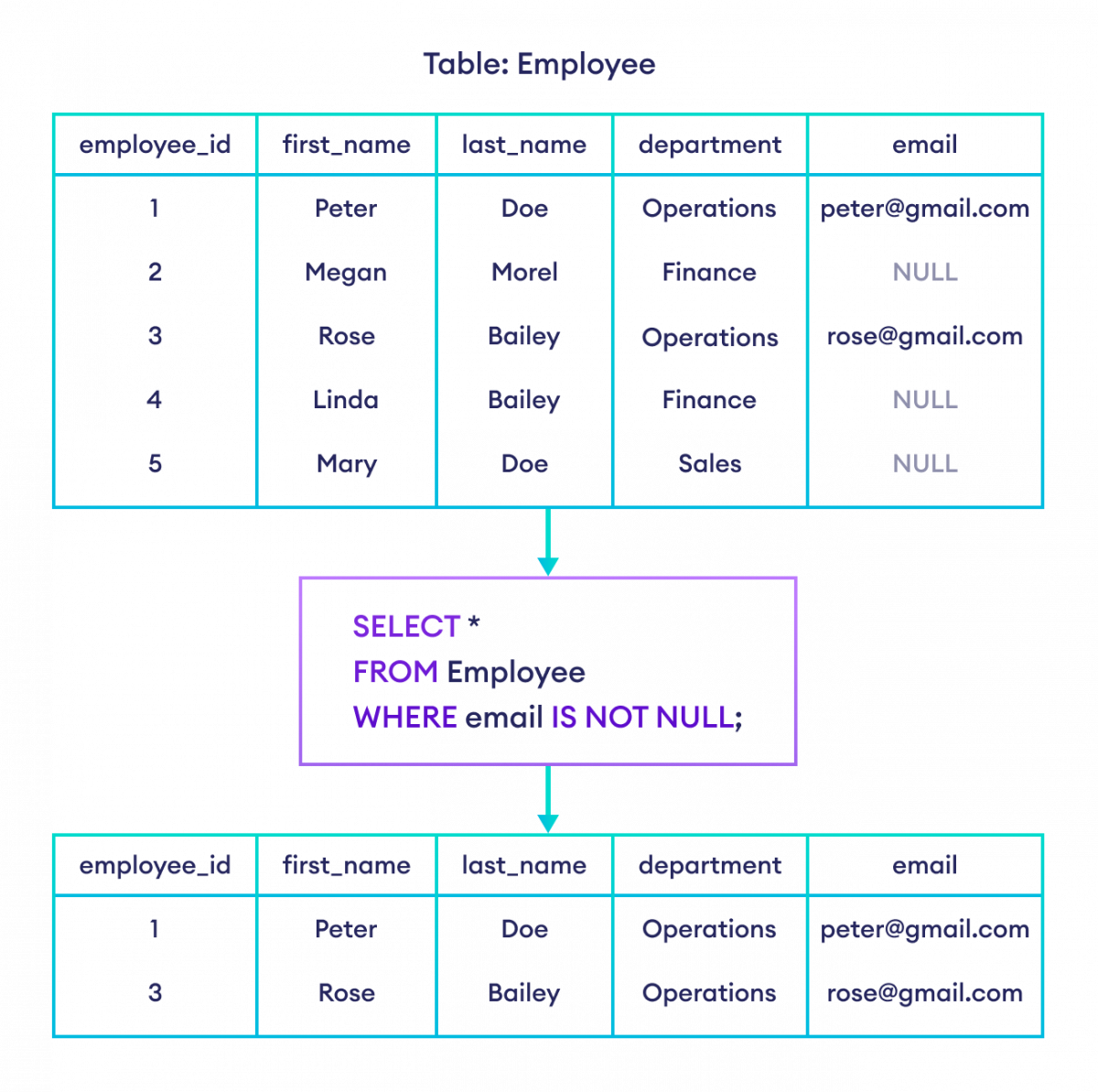
If you have a table of users and some haven't provided their middle names, those fields are NULL. If you run a query asking for everyone whose middle name is not "Edward," SQL will actually skip the people with null values. It doesn't know if their name is Edward or not, so it just stays quiet. You lose data. This is why explicitly using and not null sql syntax becomes your primary defense mechanism.
Take a look at a standard sales report. You want all transactions that aren't "Pending" but are also actually processed. If a status column allows nulls, a query like WHERE status != 'Pending' will ignore every row where the status is null. You've just deleted potentially thousands of rows from your report without realizing it.
Why Is This Happening?
It comes down to how the SQL engine evaluates the NULL state. In the ISO/ANSI SQL standard, any comparison with a NULL results in UNKNOWN.
$1 = NULL$ is unknown.
$NULL <> NULL$ is unknown.
Even $NULL = NULL$ is unknown! It's wild. Because of this, you can't use standard arithmetic operators to find these gaps. You have to use IS NOT NULL. When you’re chaining multiple conditions together, adding that extra and not null sql check ensures you are working with a concrete dataset rather than a ghost ship of missing values.
Real World Disasters and the NOT NULL Constraint
I remember a developer at a mid-sized fintech firm who nearly wiped out a loyalty points calculation. They were calculating average spend per user. They forgot that some users had joined but hadn't made a purchase yet—their last_purchase_amount was null.
✨ Don't miss: Navy Future Map of USA: What Most People Get Wrong About the 2027 Pivot
The query used a filter that accidentally dropped these users instead of treating them as zero. The result? The "average" was artificially inflated, the company over-promised rewards, and the budget took a hit.
The Performance Angle
There is a massive misconception that adding null checks slows down your database. Honestly, it's often the opposite.
When you define a column as NOT NULL at the schema level, the database engine (like PostgreSQL or SQL Server) can optimize storage. It doesn't have to keep track of a "null bitmap" for that column. According to documentation from Microsoft on SQL Server storage internals, fixed-width columns that are marked NOT NULL are generally more efficient.
If you are stuck with a legacy database where everything is nullable, you have to be surgical. Indexing columns that contain nulls can be tricky. In some systems, like Oracle, a completely null entry isn't even included in a standard B-tree index. This means if you're searching for "not null" values, the index can actually help you skip the "nothingness" and get to the data faster.
Mastering the AND NOT NULL SQL Filter
When you’re writing complex joins, the nulls like to hide.
Imagine a LEFT JOIN between a Customers table and an Orders table. If you want to find customers who have placed an order but that order hasn't been cancelled, you might write something like this:
SELECT * FROM Customers c LEFT JOIN Orders o ON c.id = o.customer_id WHERE o.status != 'Cancelled'
You just broke your query.
The LEFT JOIN includes customers who have never placed an order. For those customers, the o.status is null. Since null != 'Cancelled' is unknown, those customers disappear from your results. To fix it, you need to be explicit. You have to ensure the link exists and the data is valid by using and not null sql logic or by rethinking the join entirely.
Common Syntax Patterns
- The Direct Check:
WHERE column_name IS NOT NULL - The Combined Filter:
WHERE price > 0 AND price IS NOT NULL - The Coalesce Trick:
WHERE COALESCE(status, 'Unknown') != 'Cancelled'
The COALESCE function is a lifesaver. It lets you swap a null for a real value on the fly. But be careful. Using functions in your WHERE clause can sometimes prevent the database from using an index (this is called "non-sargable"). Whenever possible, stick to the raw IS NOT NULL check.
The Architecture Solution
If you have the power to change the table structure, do it. Use the NOT NULL constraint during CREATE TABLE.
Provide default values instead. If it’s a numeric field, maybe it should default to 0. If it’s a string, maybe an empty string '' is better than a null. However, be aware that 0 and '' carry meaning. A "0" in a temperature sensor reading is very different from a "null" (which would mean the sensor is broken).
Expert DBAs like Brent Ozar often point out that the decision to allow nulls is a business decision, not just a technical one. You have to ask: "Is 'I don't know' a valid answer for this field?" If the answer is no, lock it down.
📖 Related: MacBook Air Serial Number Check: How to Spot a Fake and Verify Your Warranty
Practical Steps for Clean Data
Start by auditing your most critical reports. Look for any WHERE clause that uses <>, !=, or NOT IN. These are the danger zones where nulls act as silent silencers for your data.
Next, check your application code. Often, a backend language like Python or Java treats a null as None or null, but the way it interacts with the database driver can vary. Always test your queries with a few "dummy" rows that contain null values to see if they show up in the results.
- Identify Nullable Columns: Use your database schema browser to see which columns allow nulls.
- Explicit Filters: In your SQL scripts, always include
AND column IS NOT NULLwhen dealing with columns that might have missing data, especially inWHEREandHAVINGclauses. - Schema Enforcement: For new tables, default to
NOT NULLunless you have a specific reason to allow missing values. - Rewrite In-Subqueries:
NOT INis notoriously broken by nulls. If a subquery returns even one null, the entireNOT INcondition evaluates to false or unknown. UseNOT EXISTSinstead.
Understanding the nuance of and not null sql is basically the difference between a junior developer and a senior data architect. It requires a mindset shift from seeing data as a perfect spreadsheet to seeing it as a messy, incomplete reflection of reality. Stop letting nulls eat your data. Check your filters, verify your joins, and always account for the unknown.
For immediate improvement, go to your most complex SQL view today and add explicit null checks to your join conditions. You will likely find a few missing rows that should have been there all along. Use the IS NOT NULL operator as your primary tool for data integrity. If you're working in a high-concurrency environment, verify that these columns are indexed properly to handle the filtered scans. Ensure that your application-level validation matches your database constraints to prevent "partial data" from ever reaching your tables.